

▶︎動画でも話してるので、文章読むのが面倒な方はこちらをみてもらえればと思います。
今回はAnimate Anyoneを利用してダンス動画を生成する方法について解説します。

これを読めば誰でも簡単にクオリティーの高いAI美女が作れるようになっているので興味がある人は、下のバナーをクリックして購入してみてね🎶

目次
Animate Anyoneを利用してダンス動画を生成する方法について
なお、この動画ではGoogle Colabを使ってAnimate Anyoneを動作させていきます。
そのため、もしもGoogle Colabというキーワードが分からない場合は、詳細を解説している記事のリンクを下記に貼っておきますので、そちらをご確認ください。
Google Colabのサイトにアクセスします
ここからの流れは下記に詳細リンクを貼っておきますので、そちらからご参照ください。
これで、Google Colabでコードを実行するための準備が整いました。
Google Colabでコードを実行
それでは早速実行していきましょう。
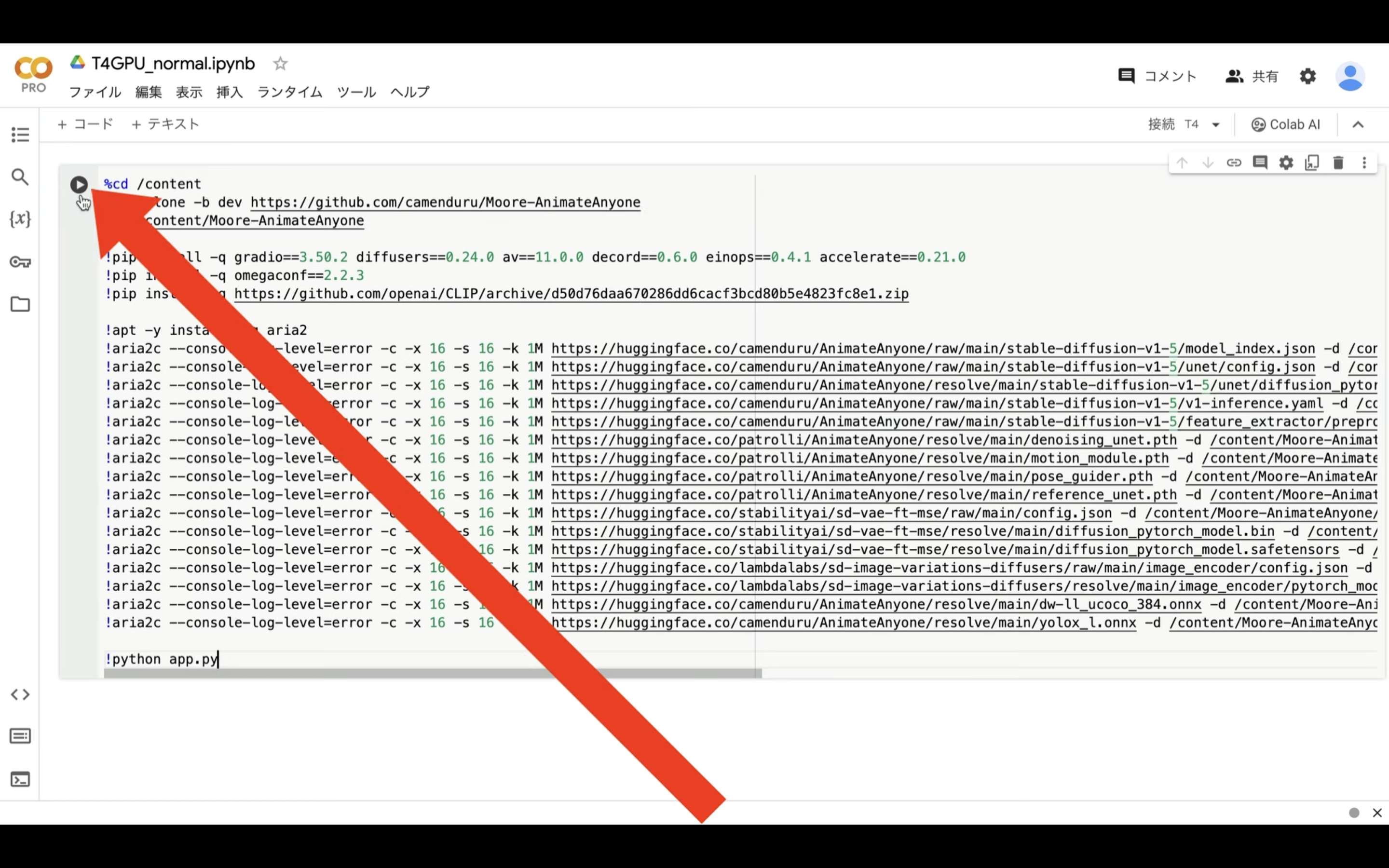
下記に貼ってあるテキストをコピーします。
%cd /content
!git clone -b dev https://github.com/camenduru/Moore-AnimateAnyone
%cd /content/Moore-AnimateAnyone
!pip install -q gradio==3.50.2 diffusers==0.24.0 av==11.0.0 decord==0.6.0 einops==0.4.1 accelerate==0.21.0
!pip install -q omegaconf==2.2.3
!pip install -q https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip
!apt -y install -qq aria2
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/model_index.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5 -o model_index.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/unet/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/unet -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/unet -o diffusion_pytorch_model.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/v1-inference.yaml -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5 -o v1-inference.yaml
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/raw/main/stable-diffusion-v1-5/feature_extractor/preprocessor_config.json -d /content/Moore-AnimateAnyone/pretrained_weights/stable-diffusion-v1-5/feature_extractor -o preprocessor_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/denoising_unet.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o denoising_unet.pth
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/motion_module.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o motion_module.pth
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/pose_guider.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o pose_guider.pth
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/patrolli/AnimateAnyone/resolve/main/reference_unet.pth -d /content/Moore-AnimateAnyone/pretrained_weights -o reference_unet.pth
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/raw/main/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/resolve/main/diffusion_pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o diffusion_pytorch_model.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/stabilityai/sd-vae-ft-mse/resolve/main/diffusion_pytorch_model.safetensors -d /content/Moore-AnimateAnyone/pretrained_weights/sd-vae-ft-mse -o diffusion_pytorch_model.safetensors
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lambdalabs/sd-image-variations-diffusers/raw/main/image_encoder/config.json -d /content/Moore-AnimateAnyone/pretrained_weights/image_encoder -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/lambdalabs/sd-image-variations-diffusers/resolve/main/image_encoder/pytorch_model.bin -d /content/Moore-AnimateAnyone/pretrained_weights/image_encoder -o pytorch_model.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/dw-ll_ucoco_384.onnx -d /content/Moore-AnimateAnyone/pretrained_weights/DWPose -o dw-ll_ucoco_384.onnx
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/AnimateAnyone/resolve/main/yolox_l.onnx -d /content/Moore-AnimateAnyone/pretrained_weights/DWPose -o yolox_l.onnx
!python app.py
テキストをコピーしたら、Google Colabの画面に戻り、テキストボックスに先ほどコピーしたテキストを貼り付け、再生ボタンを押します。
これで貼り付けたテキストの内容が実行されます。
この処理には5分以上かかると思います。
しばらく待っていると、このようなリンクが表示されます。
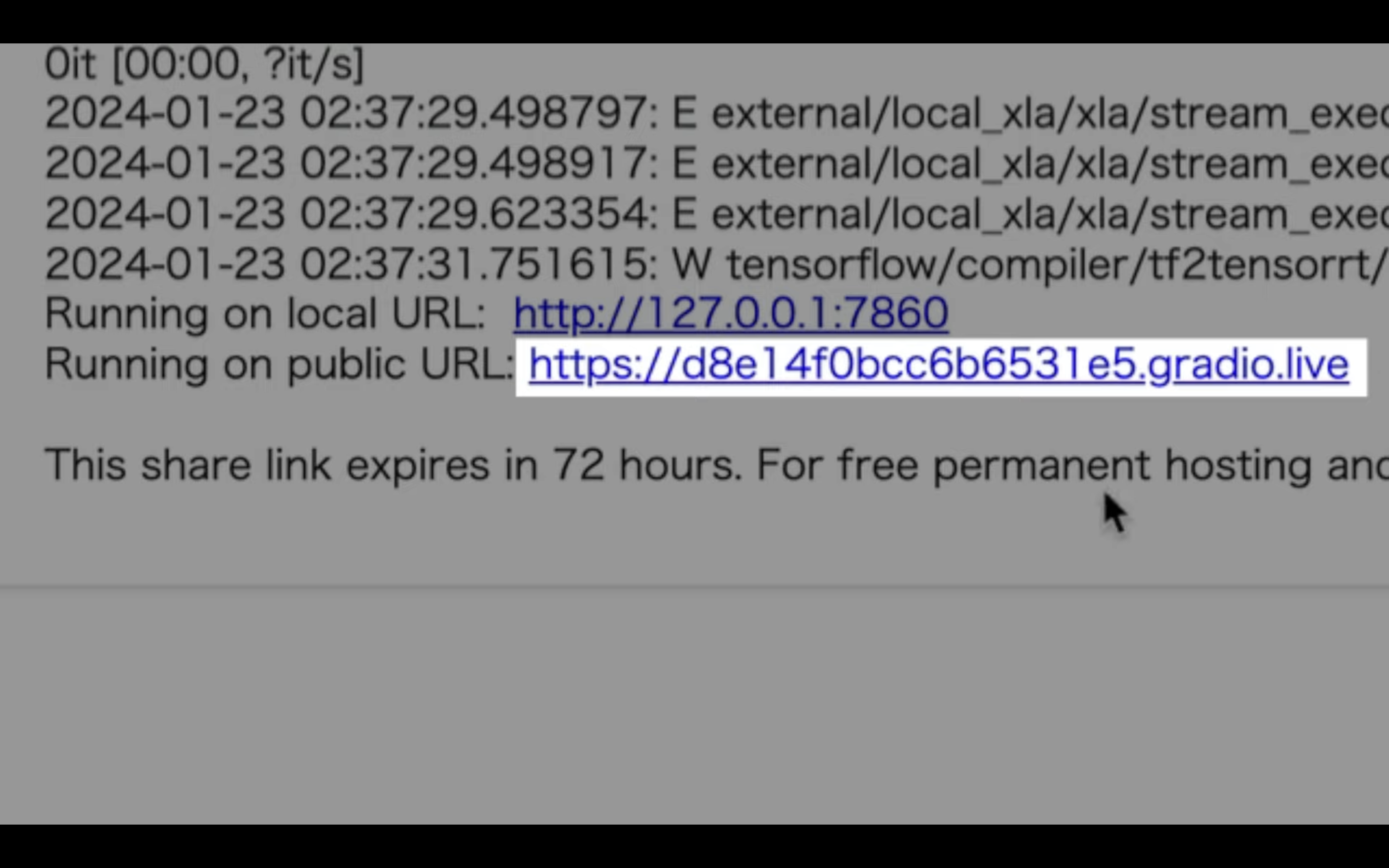
このリンクをクリックします。
そうするとAnimate Anyoneの操作画面が表示されます。
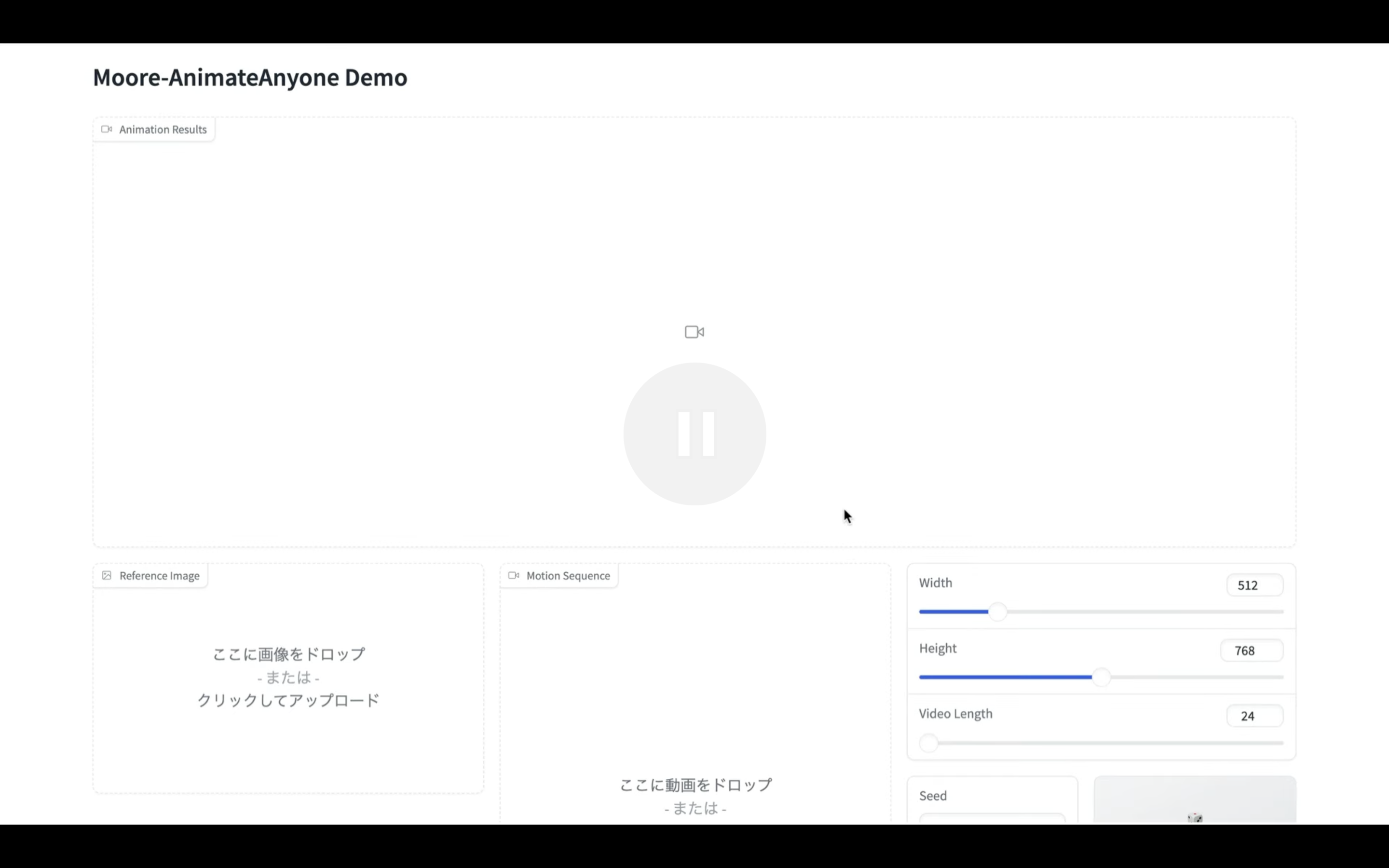
サンプルで動作を確認
まずはあらかじめ用意されているサンプルで動作を確認してみましょう。
画面をスクロールします。
そして表示されているサンプルを選択します。
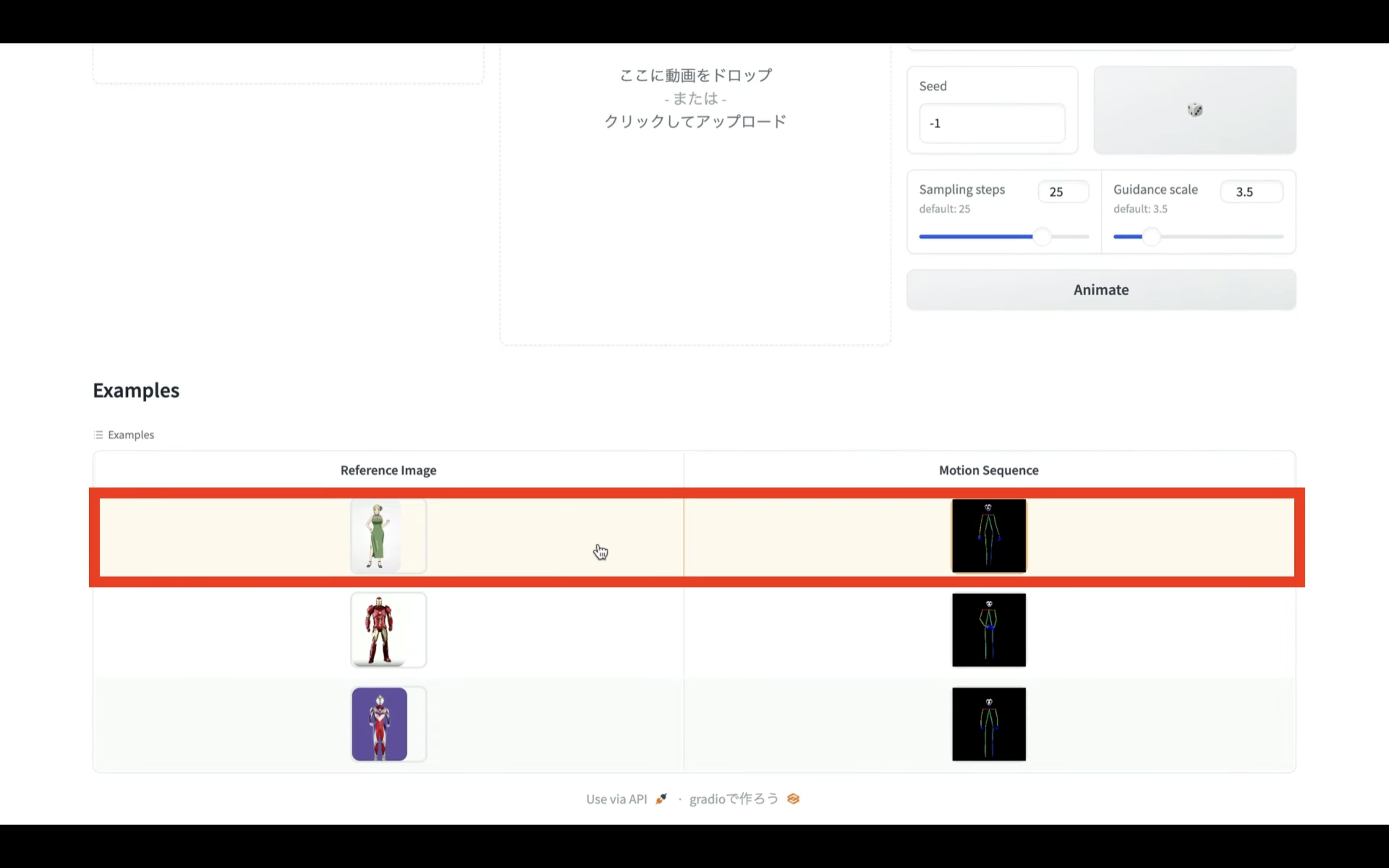
今回はこのサンプルを選択してみました。
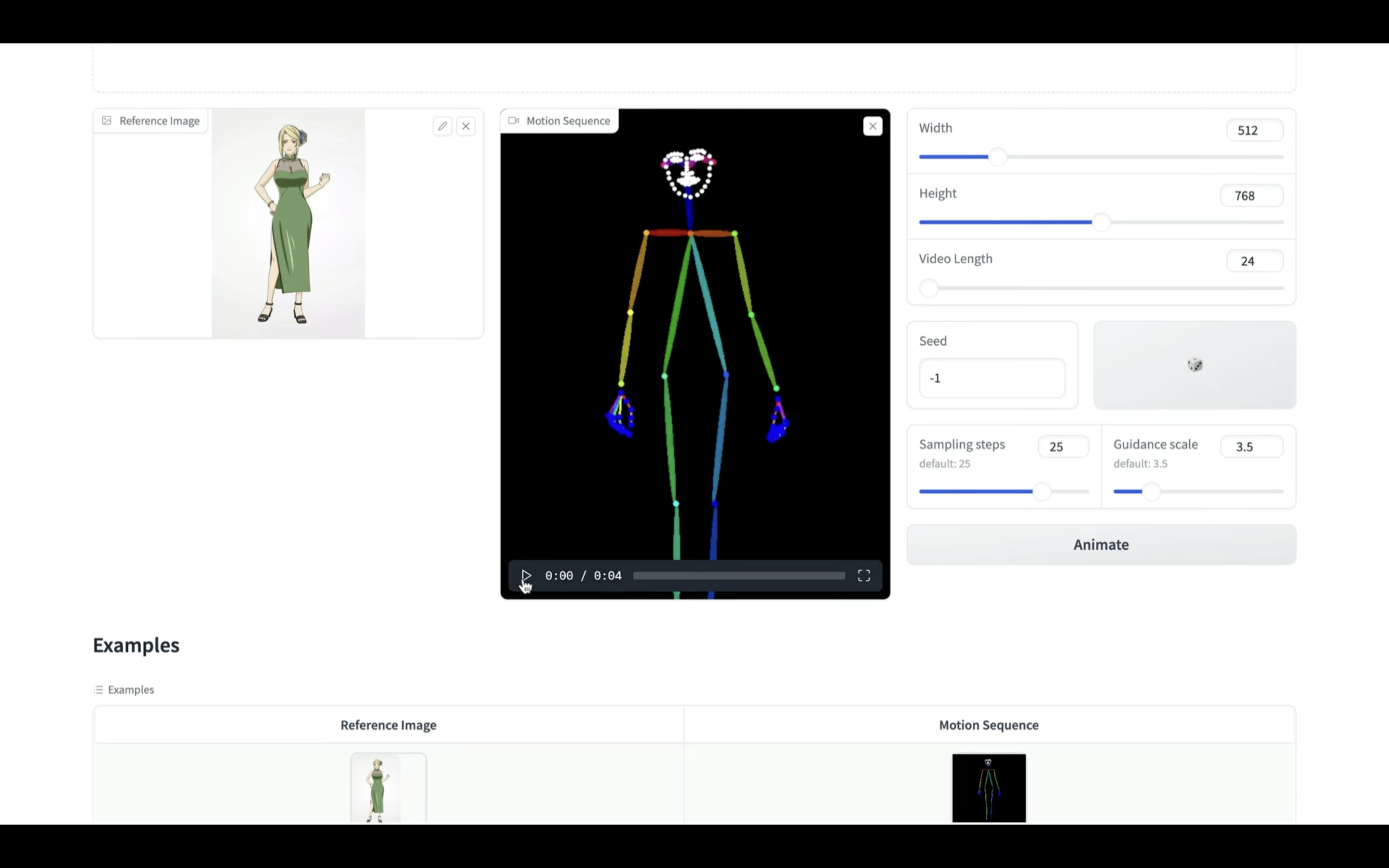
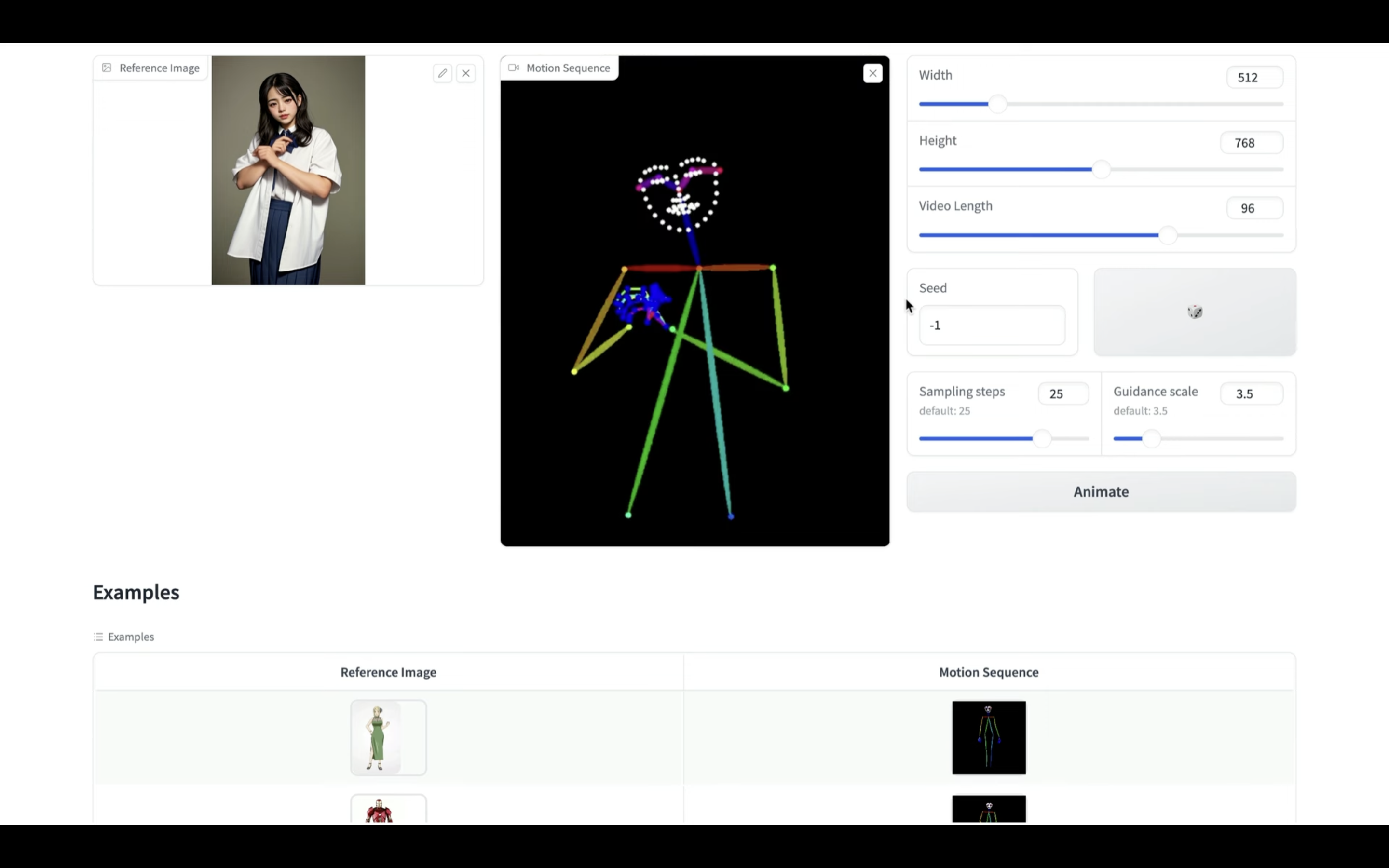
このように選択したサンプルの画像と動画が設定されています。
Animate Anyoneでは元になる画像とそれに対する動きを指定した動画ファイルを設定します。
このような動きを指定しているモーション動画の生成方法については詳細を解説している動画のリンクを下記に貼っておきますので、そちらをご確認ください。
画像と動画を設定したら、生成する動画の秒数を指定します。
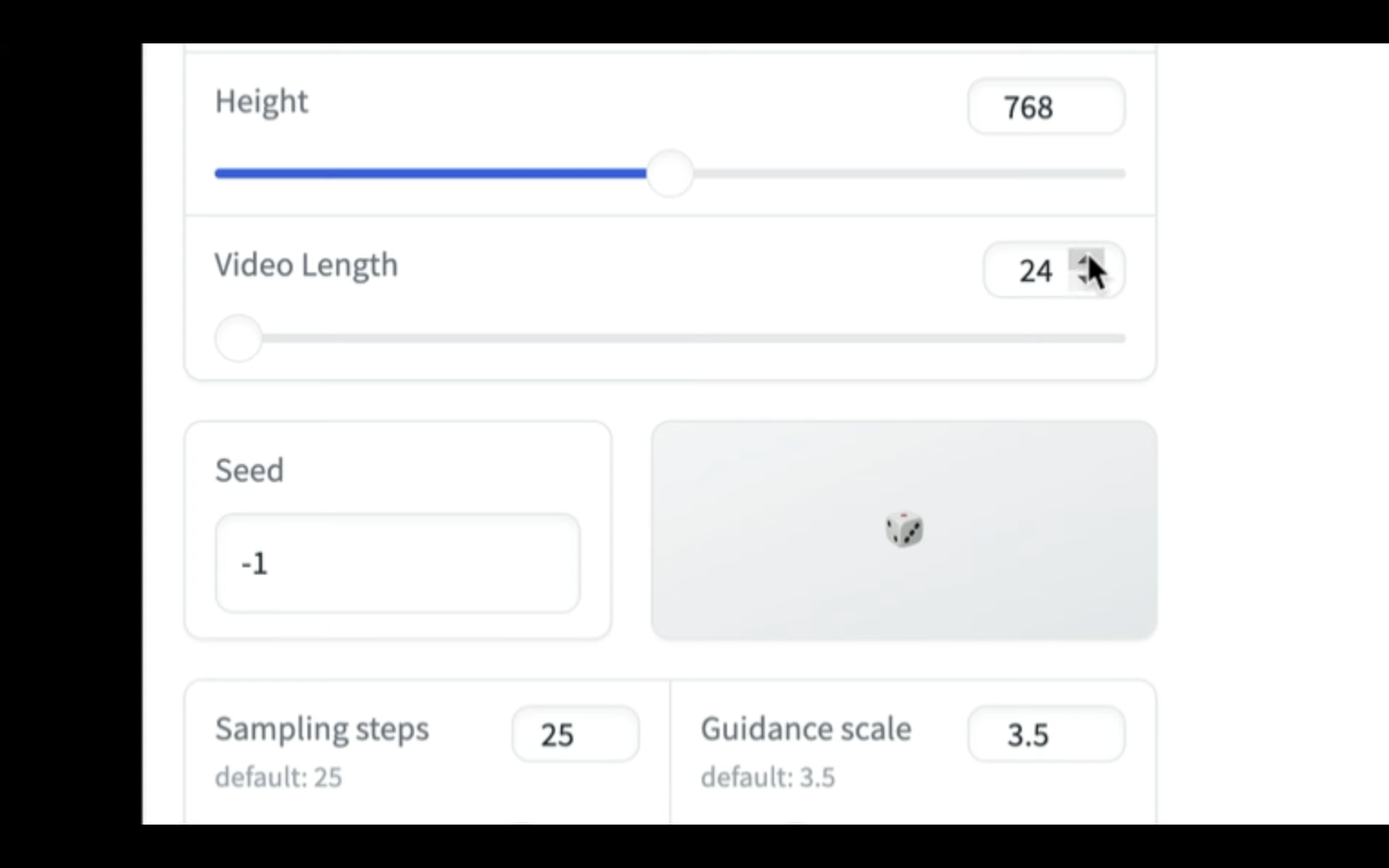
動画の長さは24で1秒の動画になります。
今回は4秒、つまり96にしておきます。
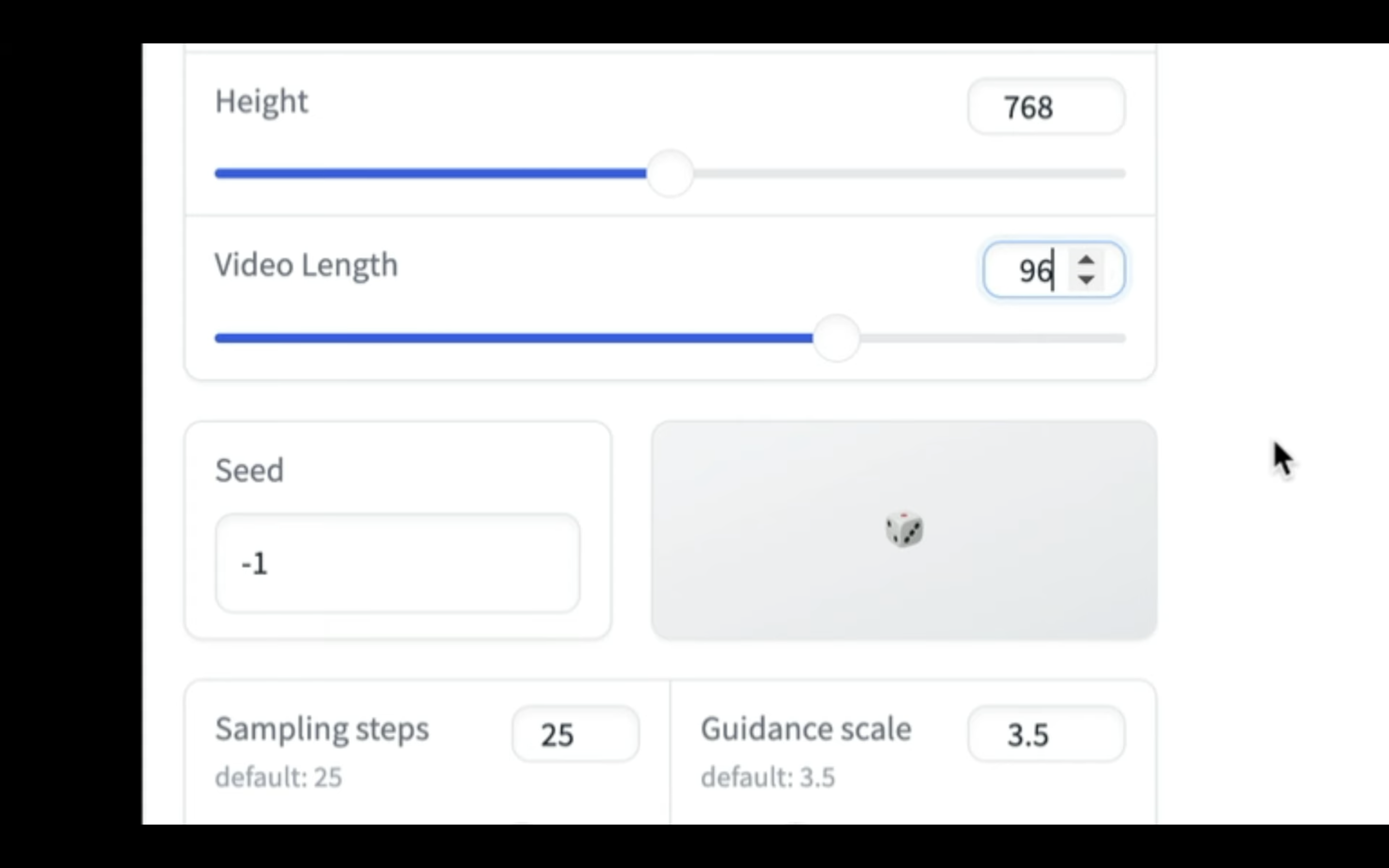
これでAnimate Anyoneの動画を生成するための準備が整いました。
動画を生成
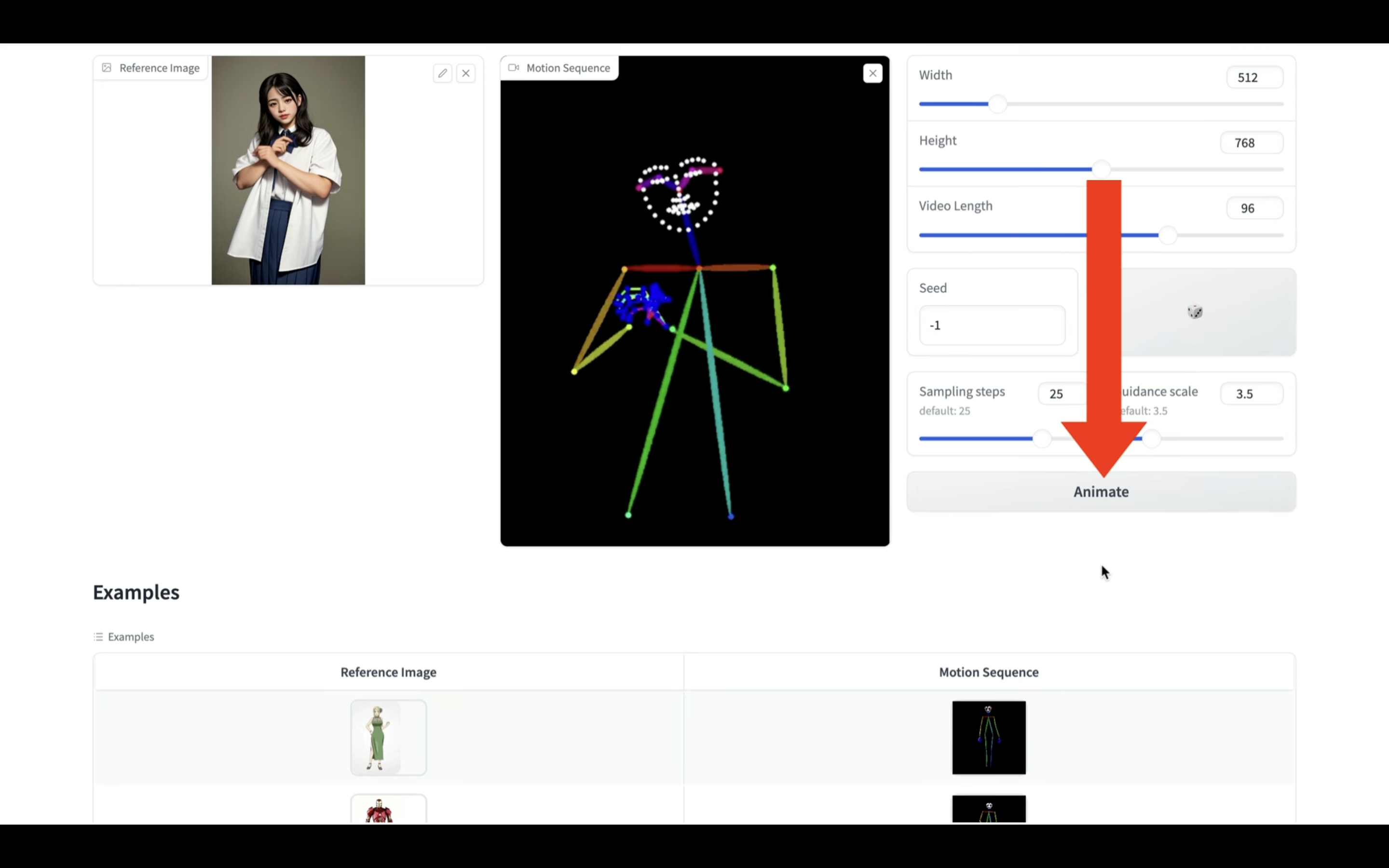
Animateと書かれているボタンをクリックします。
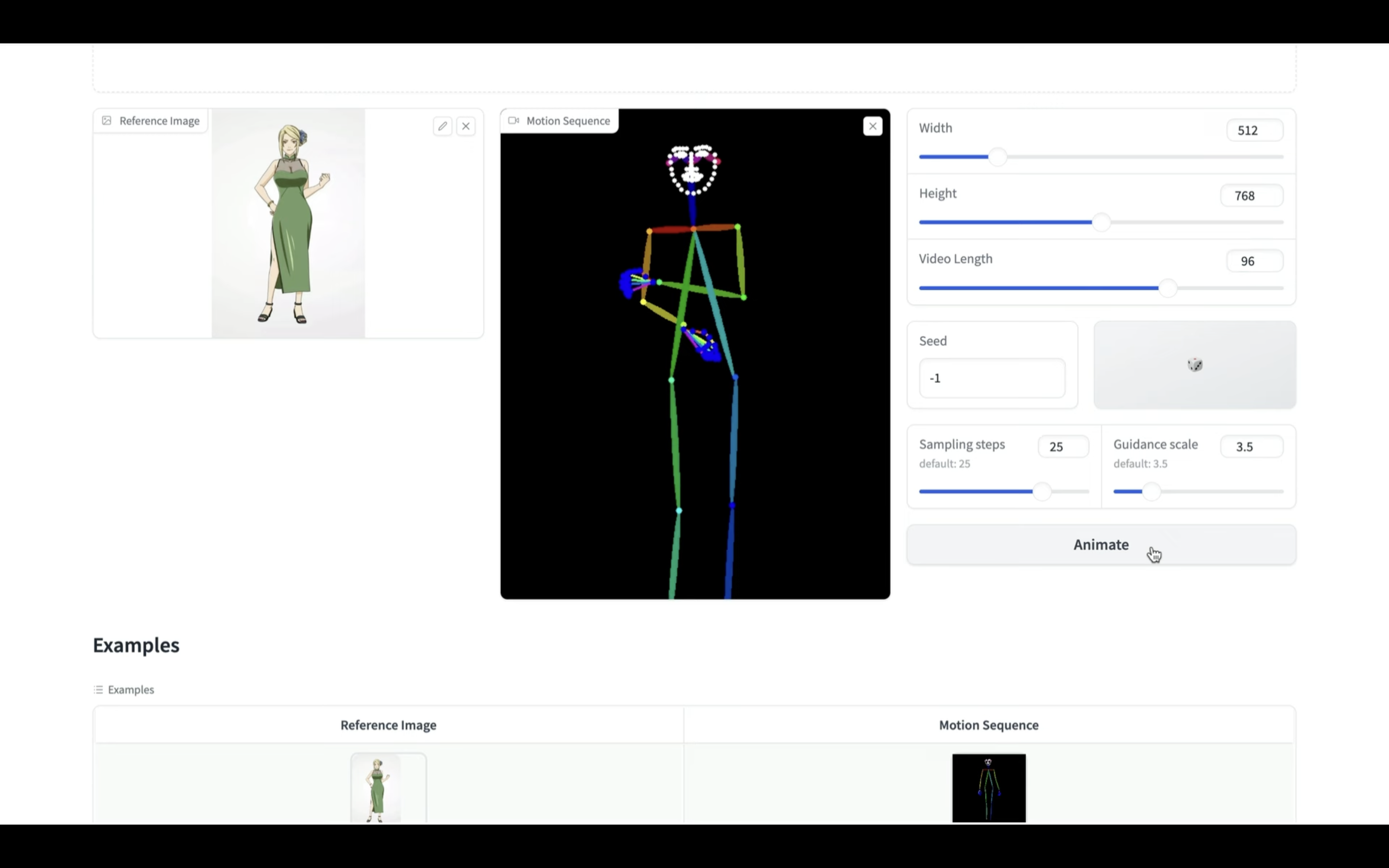
そうすると動画の生成が開始されます。
動画の長さにもよりますが、動画が生成されるまでには20分以上かかることもあると思います。
しばらく待っていると、このような動画が生成されました。
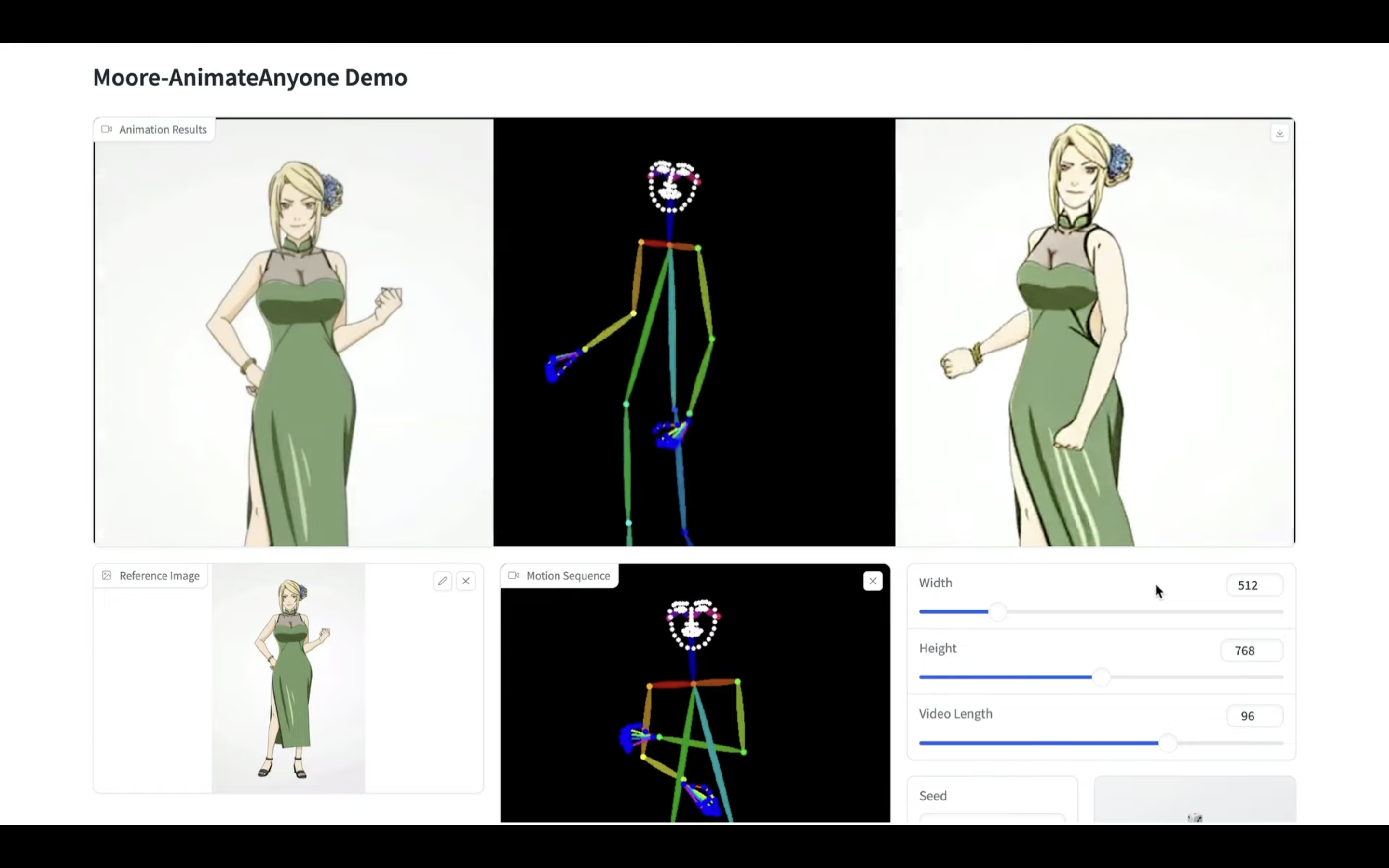
こんなに簡単に動画が生成できるのは便利ですね。
生成された動画をダウンロードするには、右上にあるダウンロードのマークをクリックします。
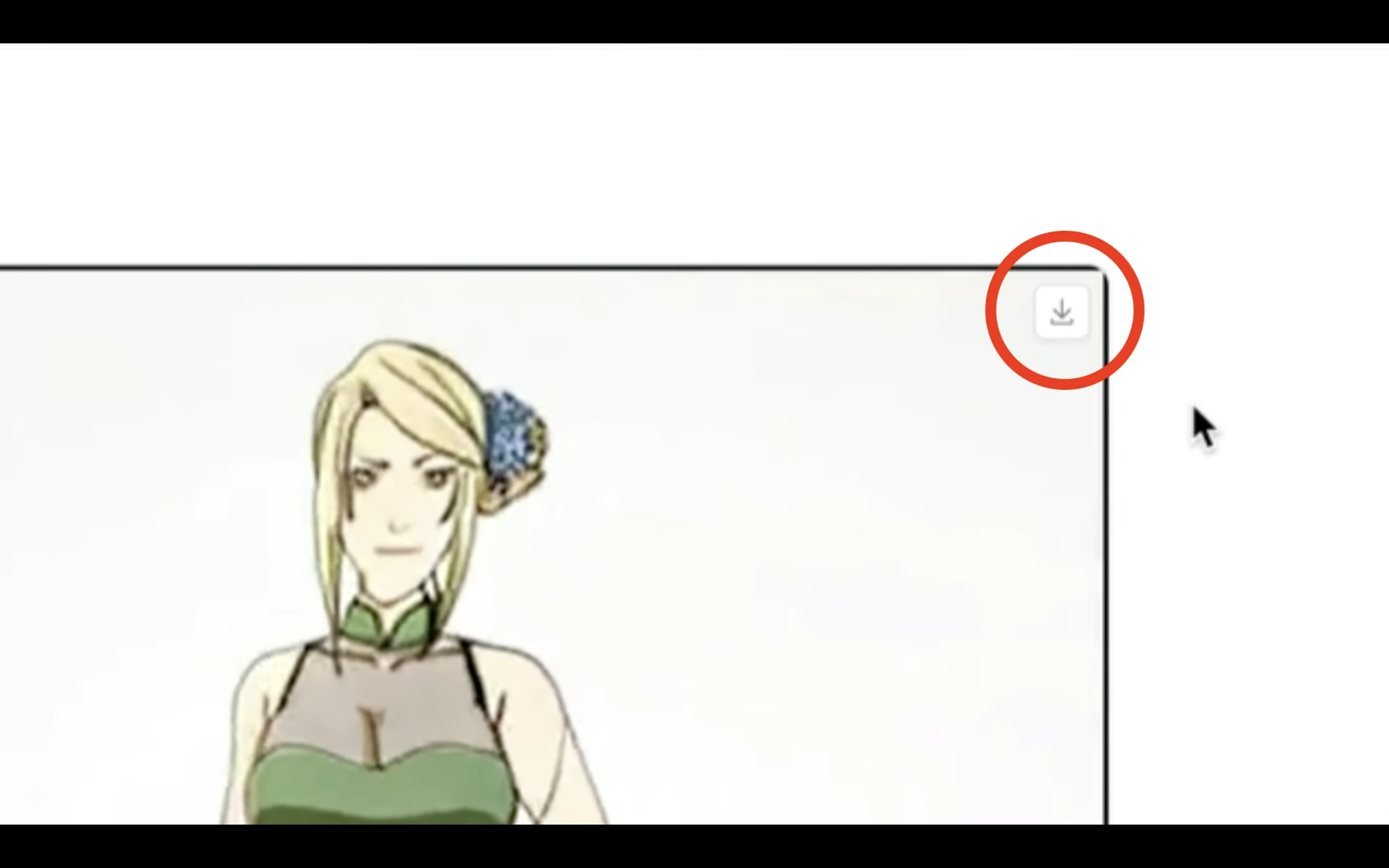
これでパソコンに生成された動画ファイルを保存することができます。
別の動画を生成
選択している画像と動画を削除します。
そしてこの部分に画像ファイルをドラッグ&ドロップします。
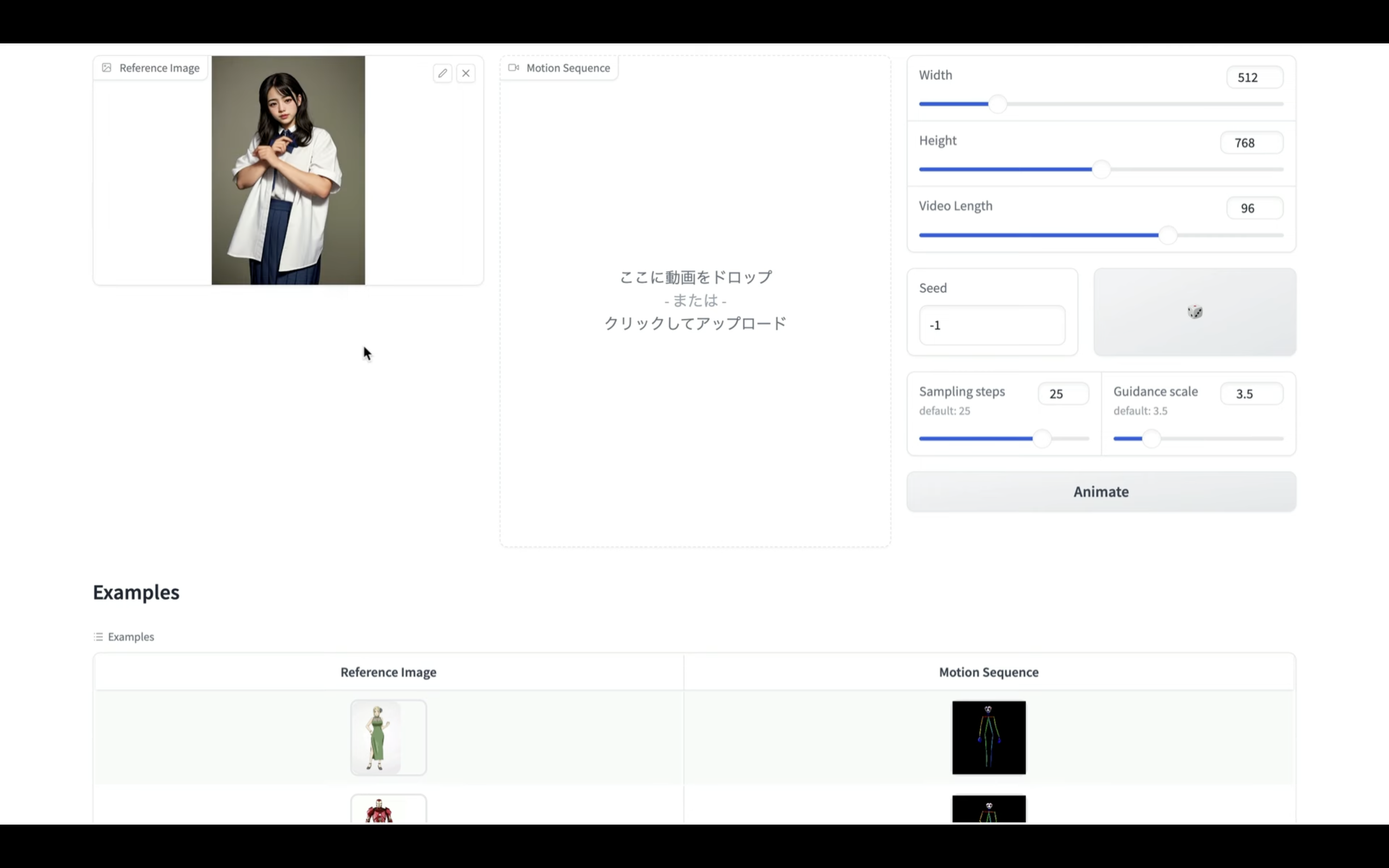
今回はこのような画像をアップロードしておきました。
次に動画ファイルをこの部分にドラッグ&ドロップします。
今回はこのようなモーション動画をアップロードしてみました。
画像と動画を指定したら、Animateボタンをクリックします。
動画の生成処理が開始されるのでしばらく待ちます。
しばらく待っていると、このような動画が生成されました。
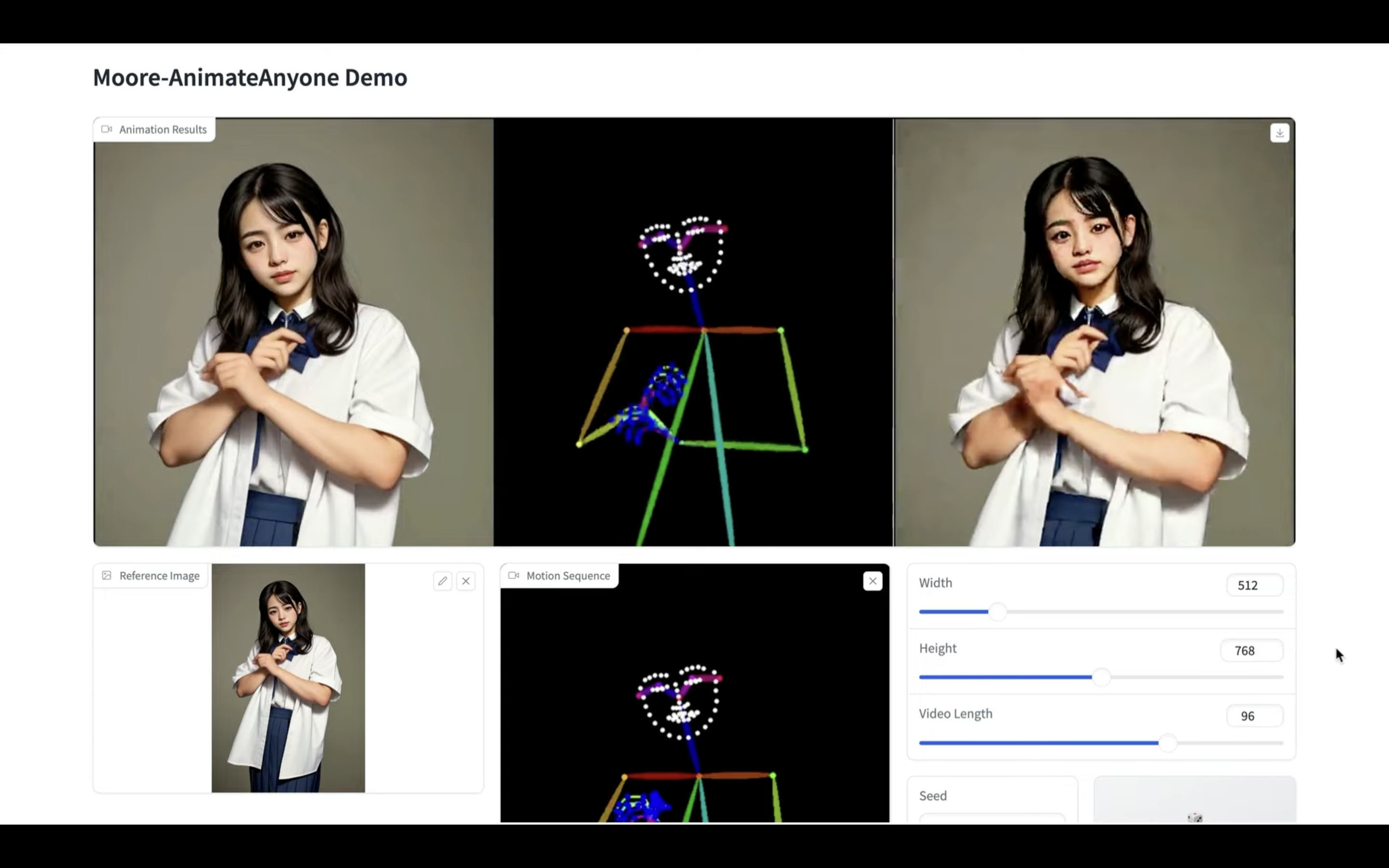
顔や手の崩れが気になりますが、それでも画像ファイルからこのようなダンス動画ができるのはすごいですね。
是非お試しください。






