

▶︎動画でも話してるので、文章読むのが面倒な方はこちらをみてもらえればと思います。
今回は1枚の顔写真から顔の表情を変えた動画を作成する方法について解説します。

これを読めば誰でも簡単にクオリティーの高いAI美女が作れるようになっているので興味がある人は、下のバナーをクリックして購入してみてね🎶

目次
1枚の顔写真から表情が変わるアニメーション動画を作成する方法
この動画を最後まで見ていただければ1枚の顔写真と表情を変えている動画を組み合わせてこのような動画を作成する方法を理解することができます。
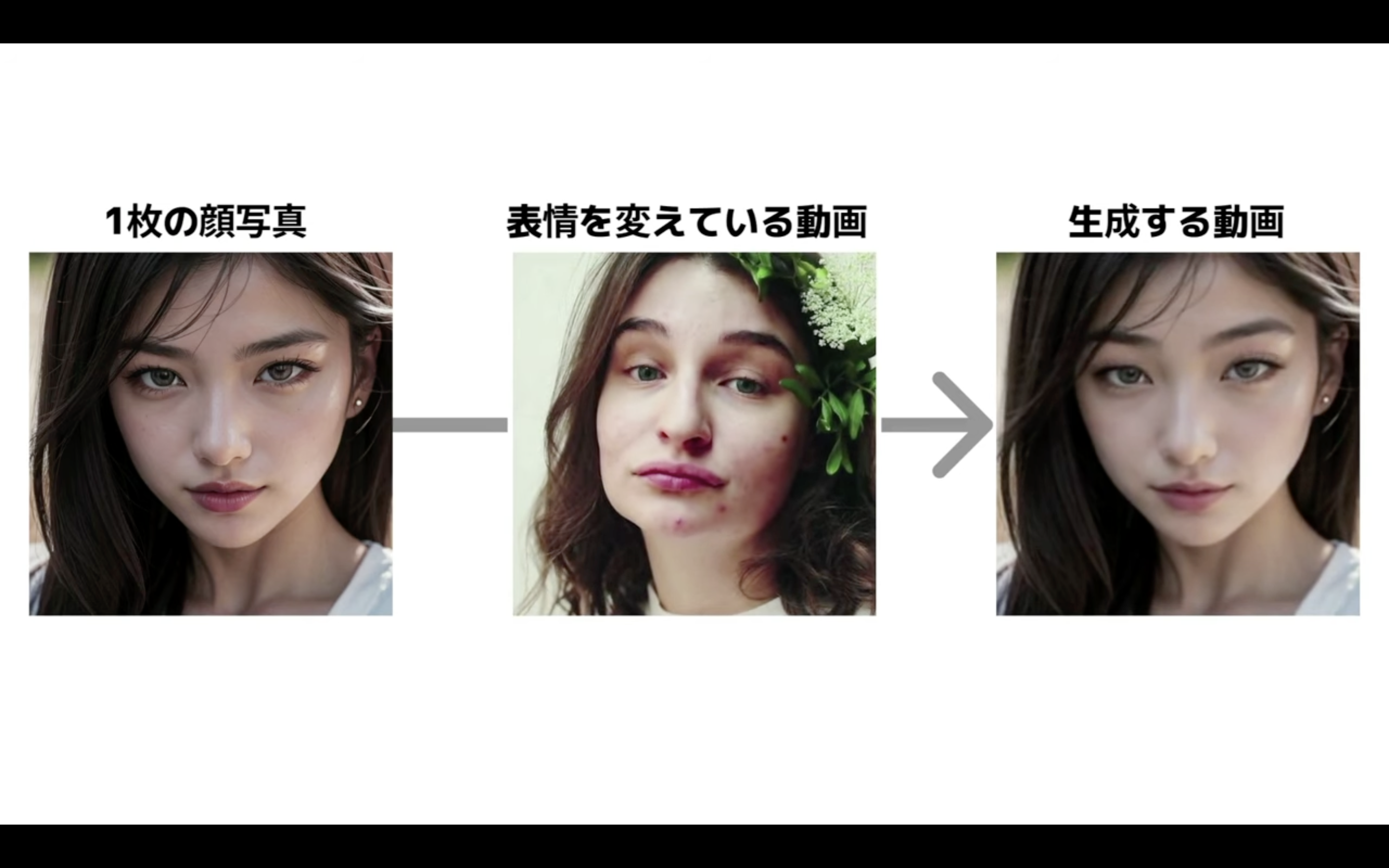
今回のような動画を作成するためには公開されているソースコードを利用します。
このサイトへのリンクは以下に貼っておきますので、そちらをご確認ください。
Google Colabを使ってプログラミングを実行する
この解説では、このソースコードをGoogle Colabで実行します。
Google Colabはクラウド上でプログラミングを実行することができるGoogleが提供しているツールです。
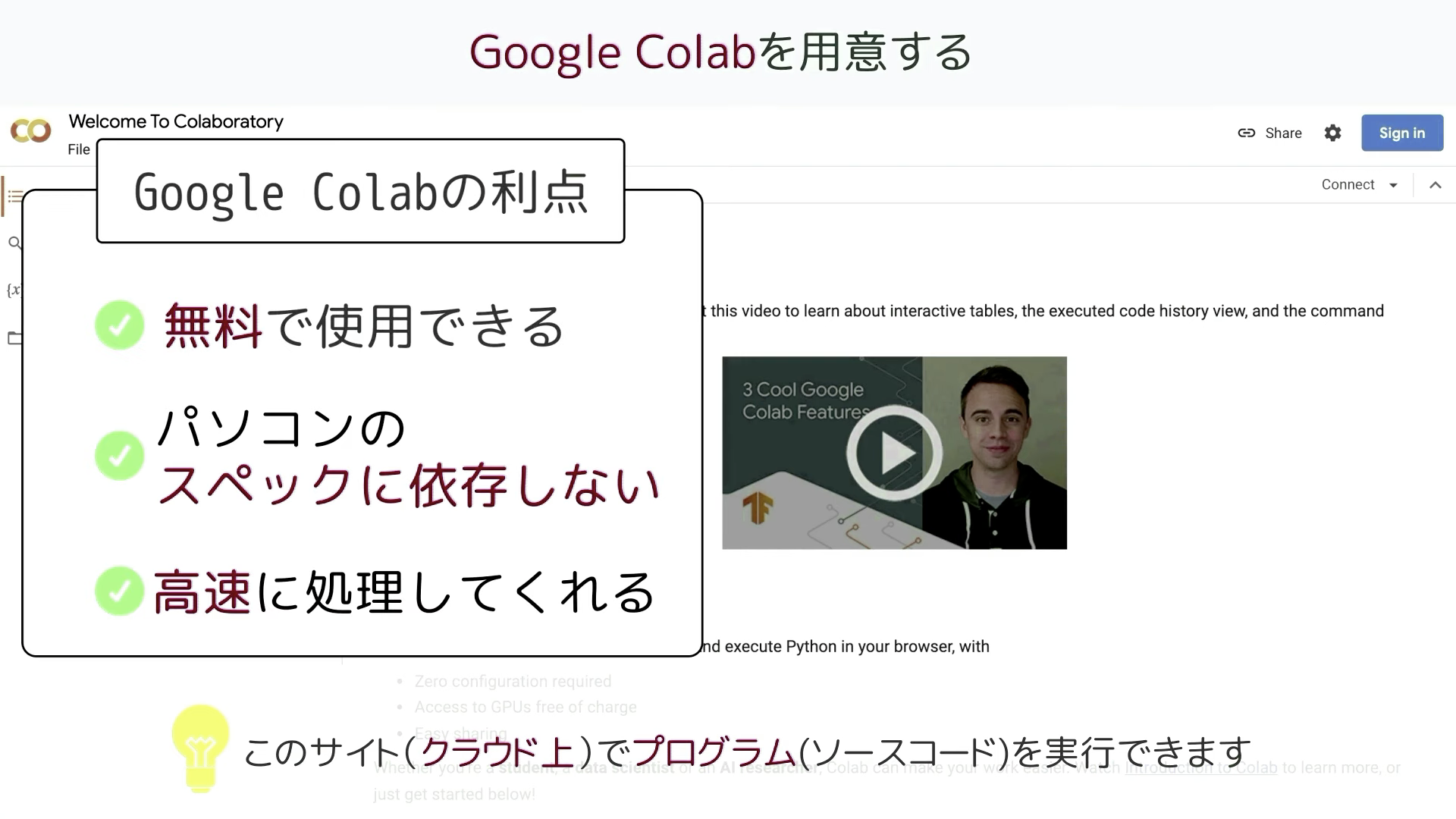
無料で使用することができ、自分のパソコンのスペックに依存せず高速な処理を行うことができるのが大きな利点です。
Googleアカウントを持っていれば誰でもGoogle Colabを使用することができます。
Google ColabのURLを貼っておきますのでそちらをご確認ください。
Google Colabのサイトにアクセスしたら、このような画面が表示されると思います。
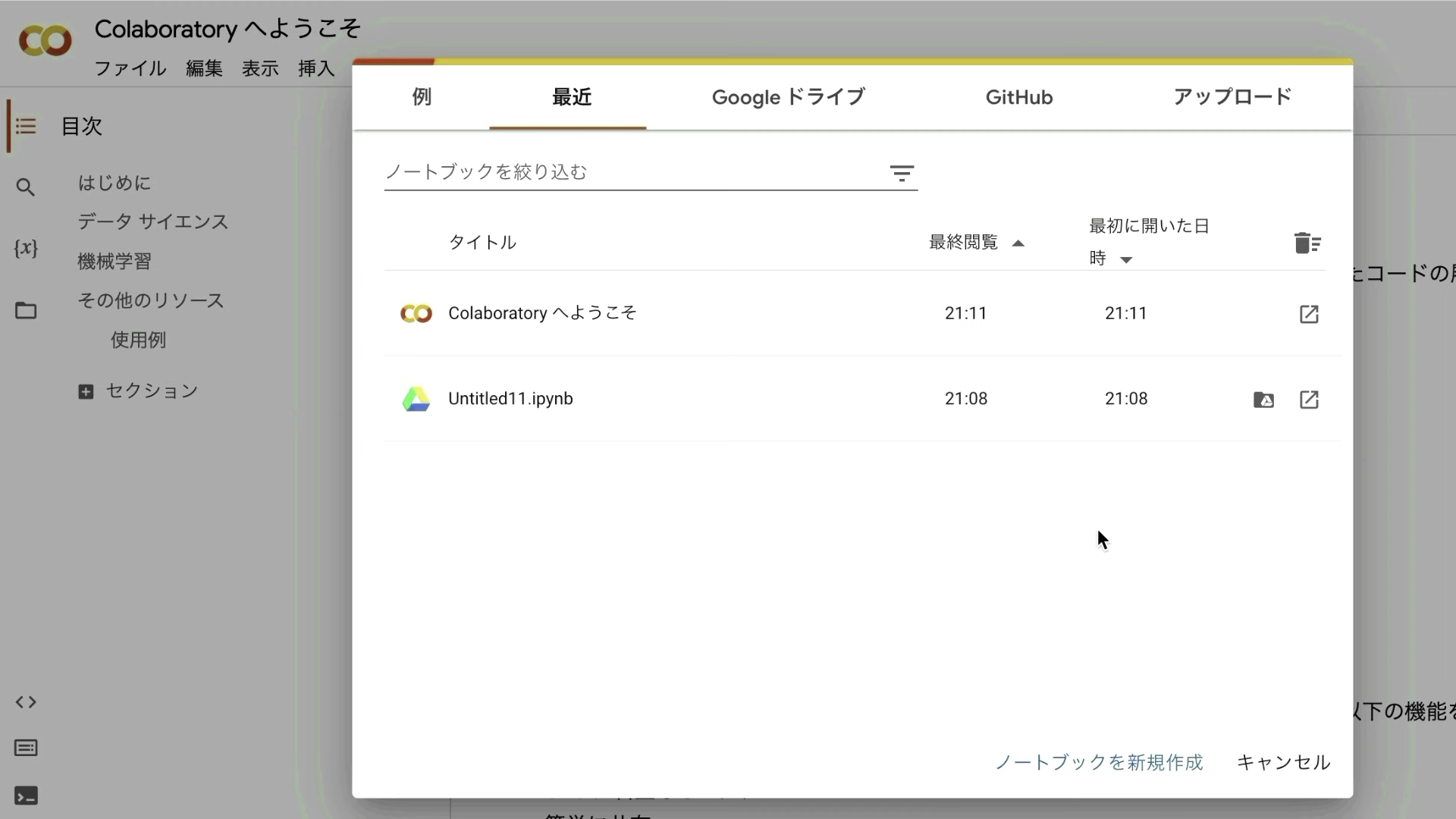
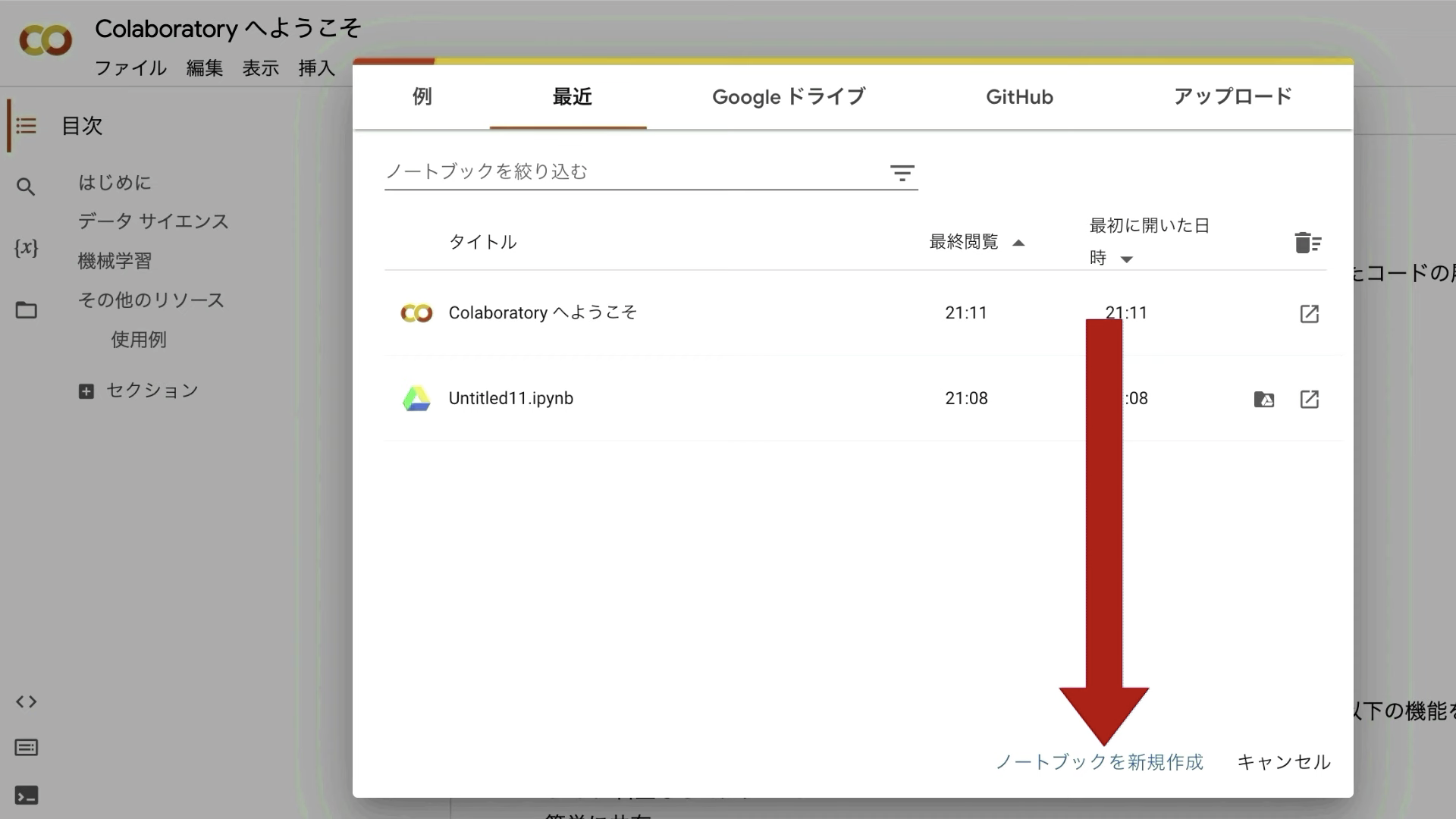
表示されているポップアップ画面の右下にある「ノートブックを新規作成」と書かれているテキストをクリックします。
次にランタイムのボタンをクリックし、「ランタイムのタイプを変更」をクリックします。
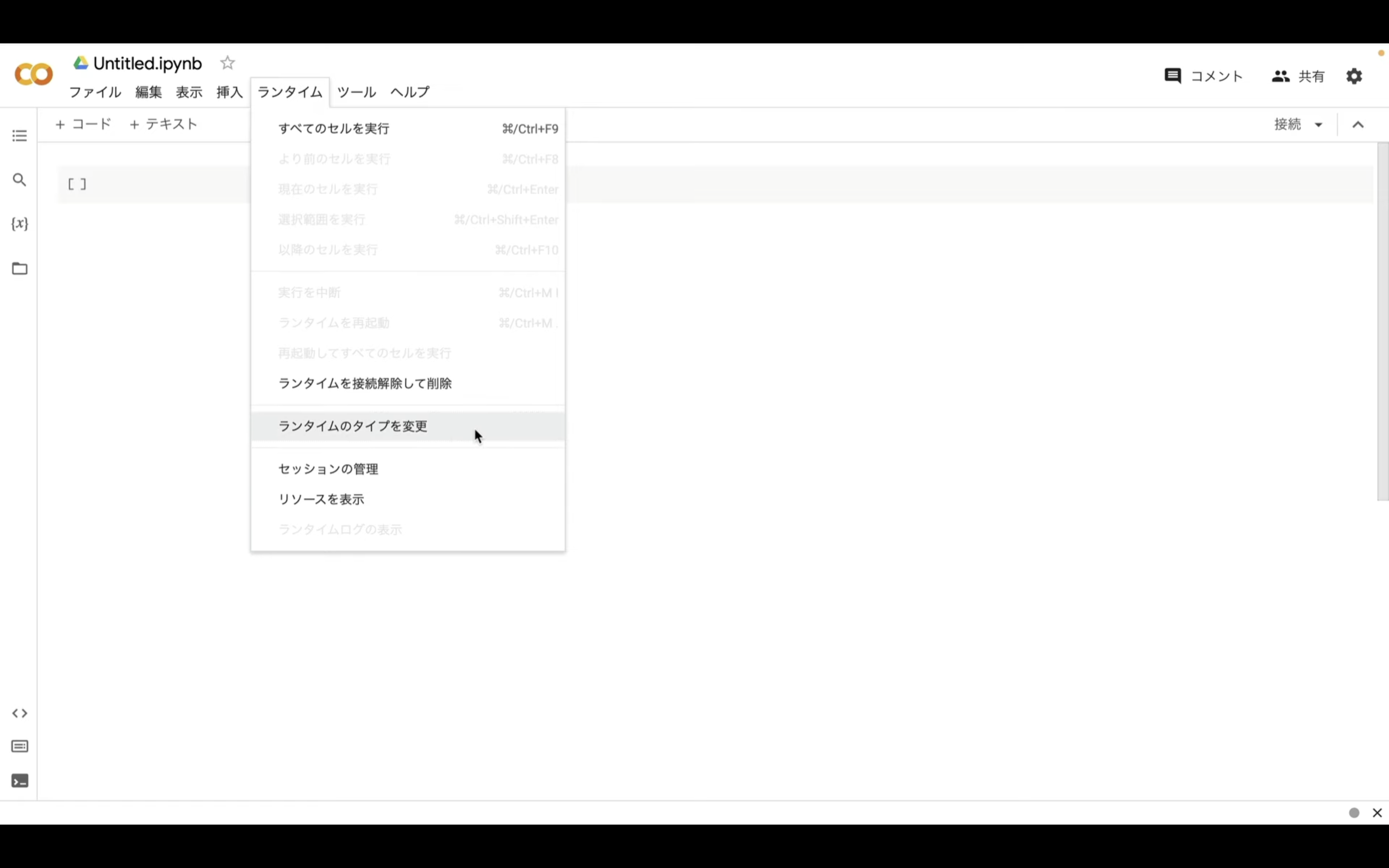
ランタイムのタイプはPython3のままで大丈夫です。
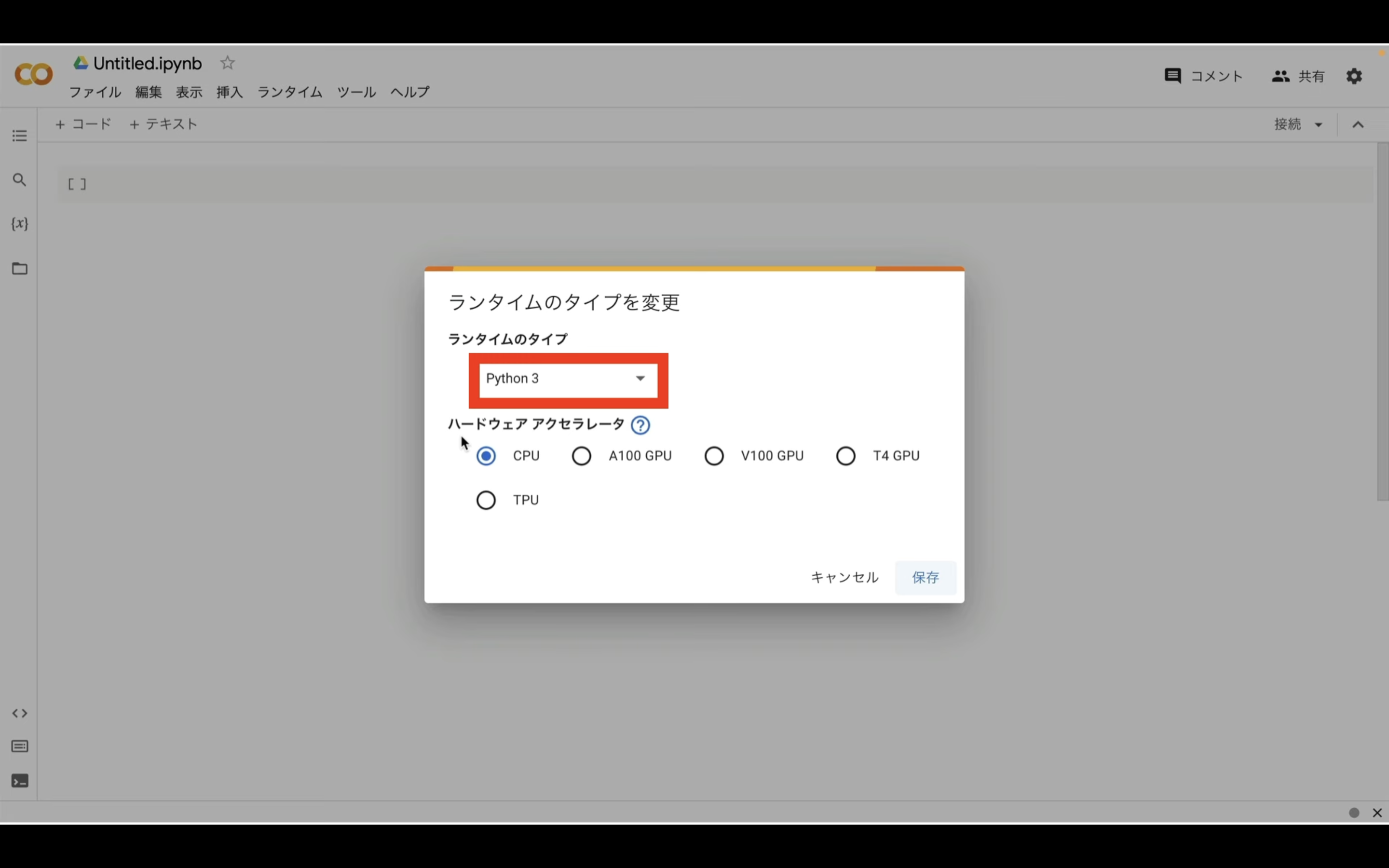
ハードウェアアクセラレーターはT4 GPUを選択しておきましょう。
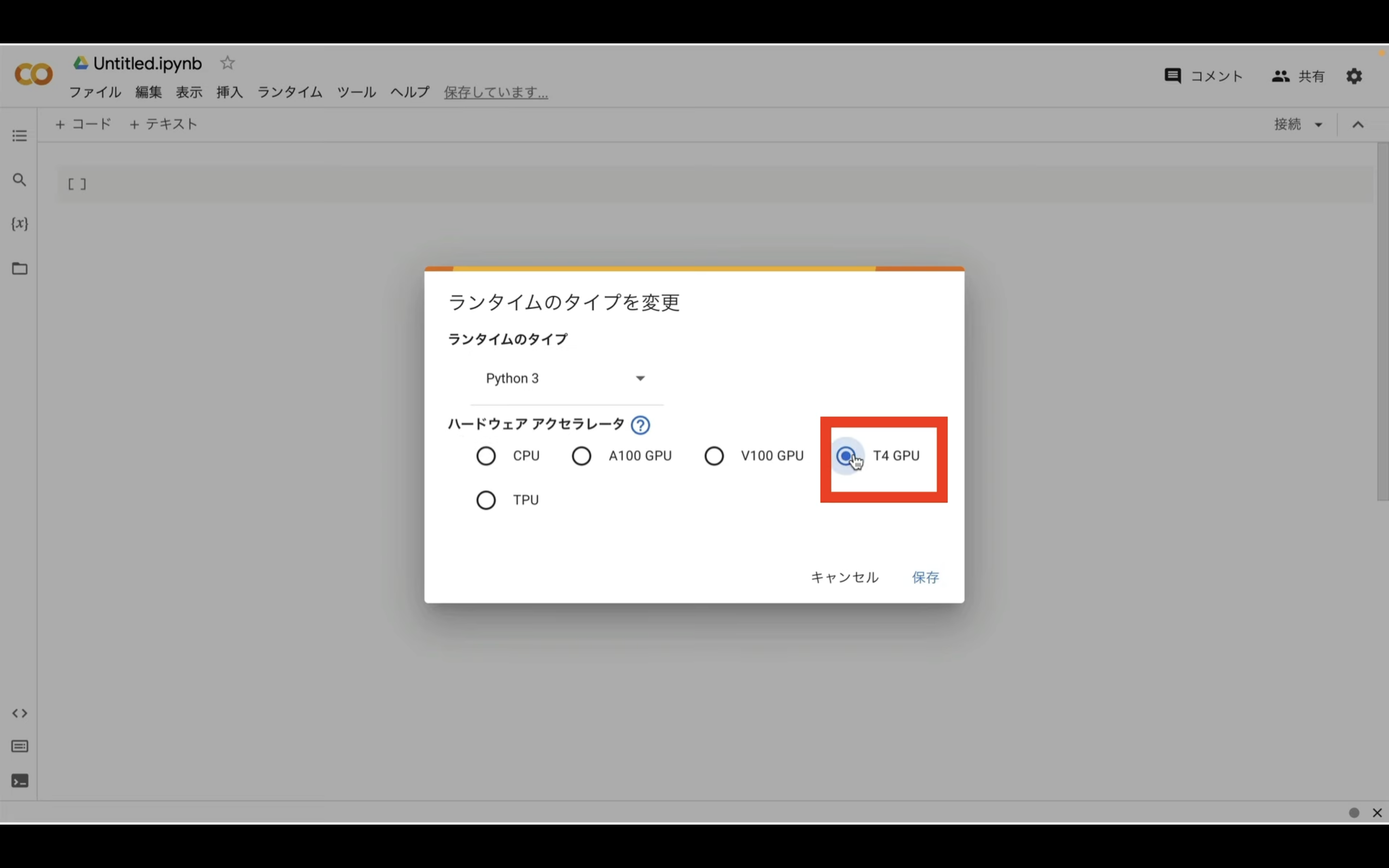
ノートブックの設定を指定したら右下の保存ボタンをクリックします。
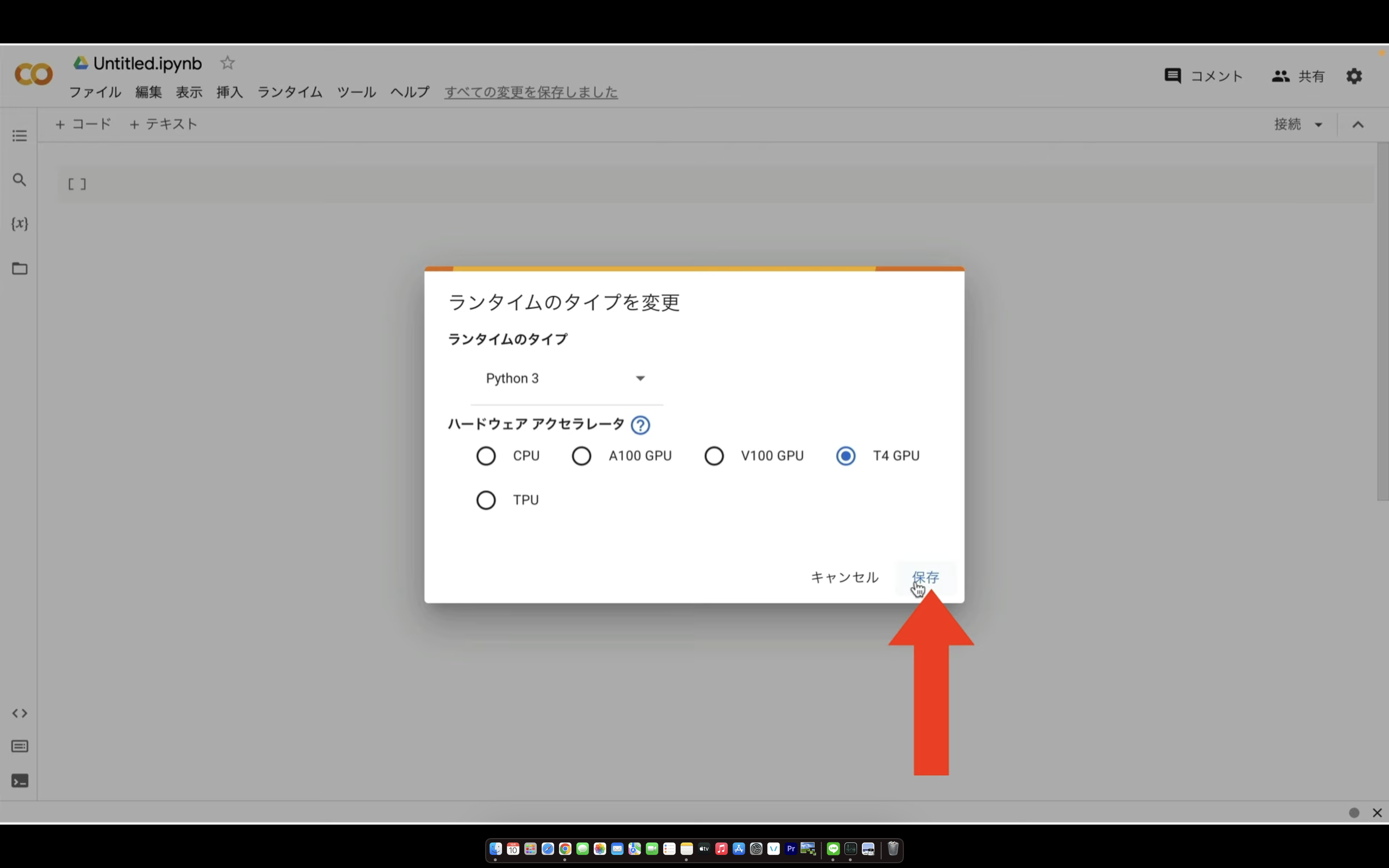
これでGoogle ColabでFaceFusionを実行するための準備が整いました。
先ほど説明しましたが、Google Colabは無料で利用できます。
ただし、無料版だとリソースの割り当てが保証されていません。
そのため、強制的にコードを終了されてしまうことがあります。
最近はGoogle Colabを利用するユーザーが増えていますので、無料版に割り当てられるGoogle Colabのリソースが減ってしまっています。
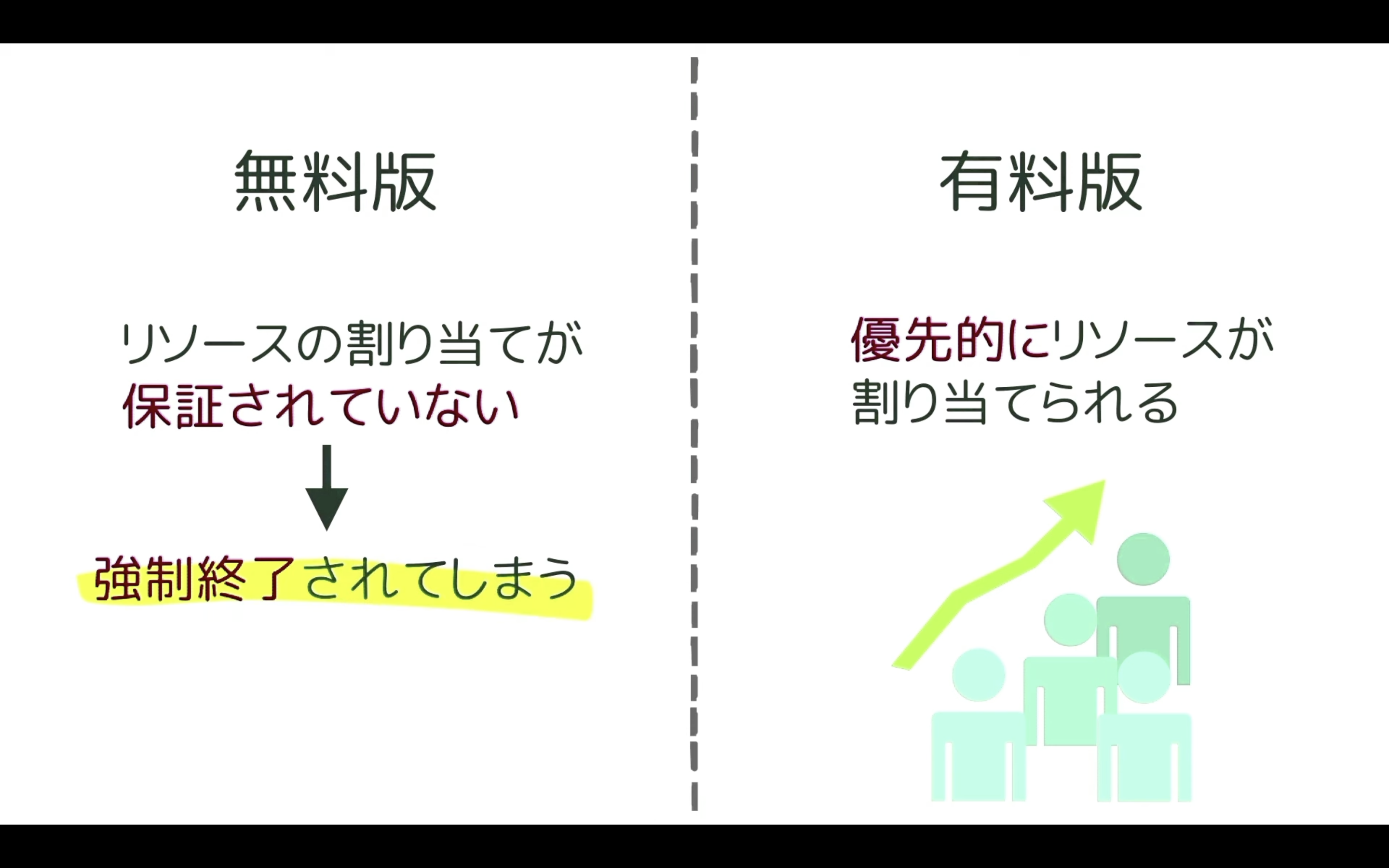
その結果、無料版では以前より実行中のコードが強制終了されてしまうことが多くなってきました。
具体的にはコードの実行が強制的に終了された場合はこのような画面になります。
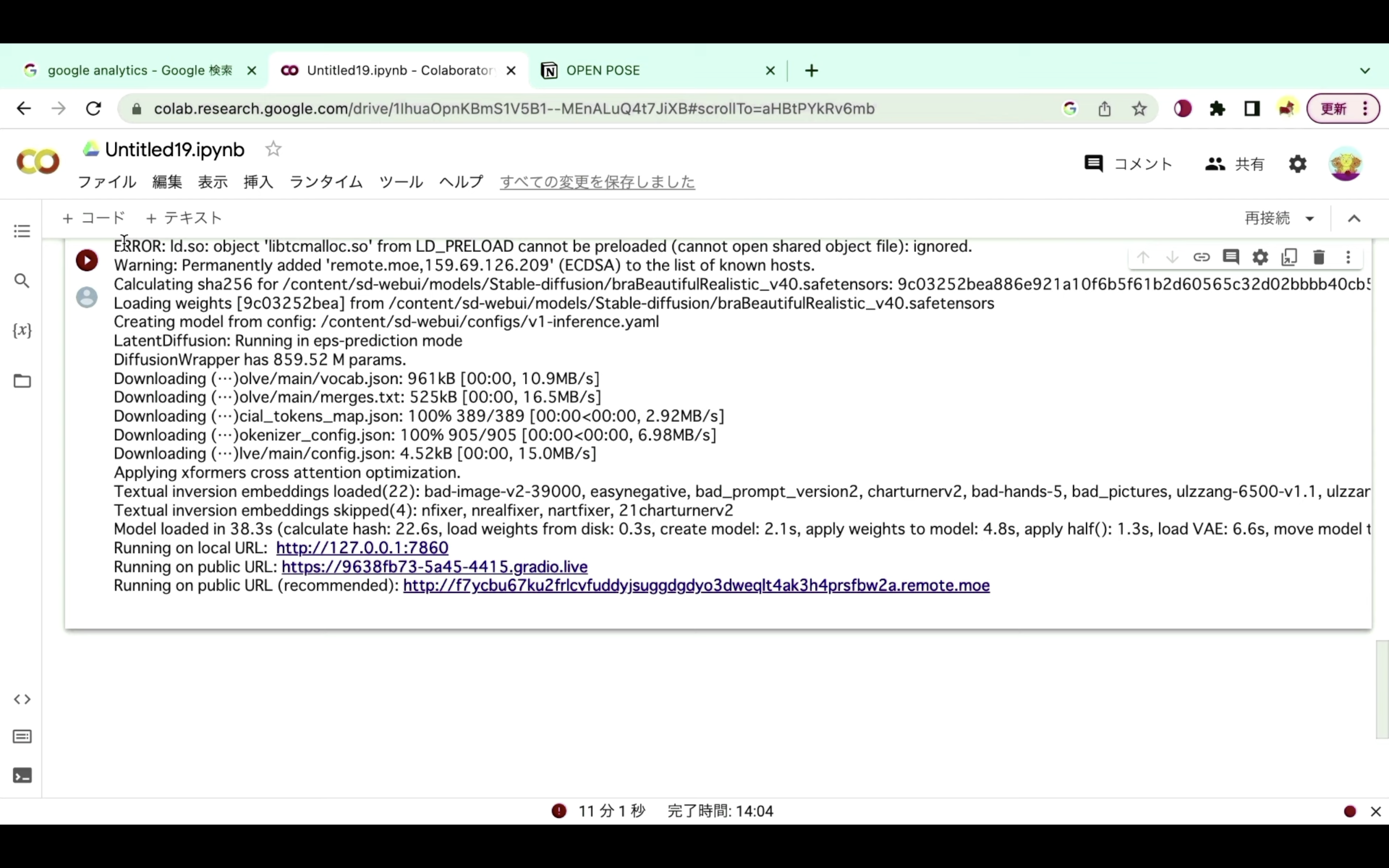
再生ボタンの部分が赤くなっているもしくは赤いびっくりマークのアイコンが表示されている場合は、コードが強制的に中断されたと判断していいと思います。
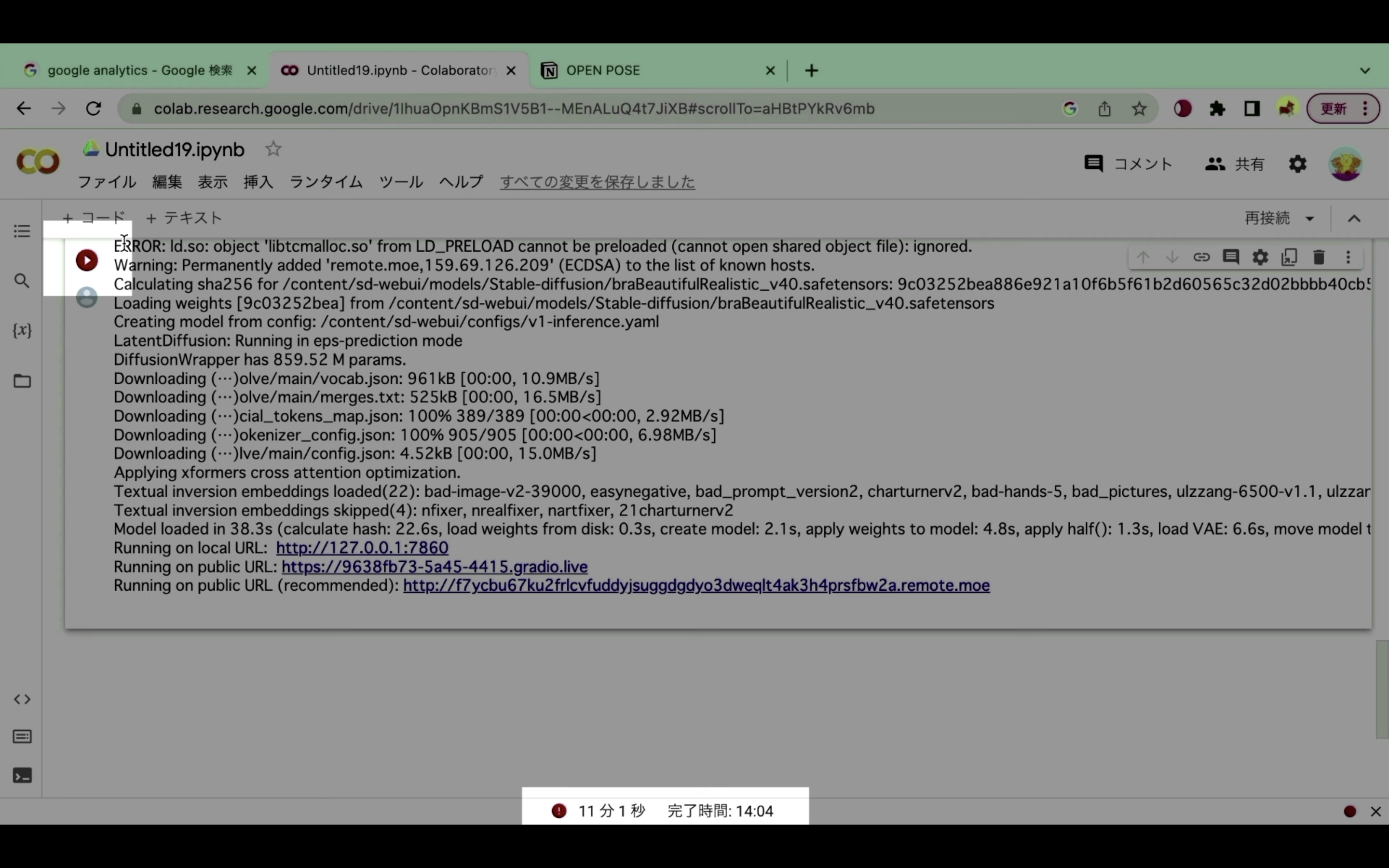
強制的に中断されてしまう状況が続くようであれば、有料プランへの切り替えをお勧めします。
有料プランへの切り替え方法については詳細を解説している動画のリンクに貼っておきますので、そちらをご確認ください。
なお、ここからは有料版に切り替えた状態で解説を進めます。
Google Colabを有料版に切り替えた状態で解説
まずはテキストをコピーします。
import os
from google.colab import files
# remove previous input video
if os.path.isfile('/content/video.mp4'):
os.remove('/content/video.mp4')
if os.path.isfile('/content/face.png'):
os.remove('/content/face.png')
%cd /content
uploaded = files.upload()テキストをコピーしたらGoogleコラボの画面に戻ります。
テキストボックスにコピーしたテキストを貼り付けます。
テキストを 貼り付けたら左上にある再生ボタンをクリックします。
そうするとファイルをアップロードするためのボタンが表示されます。
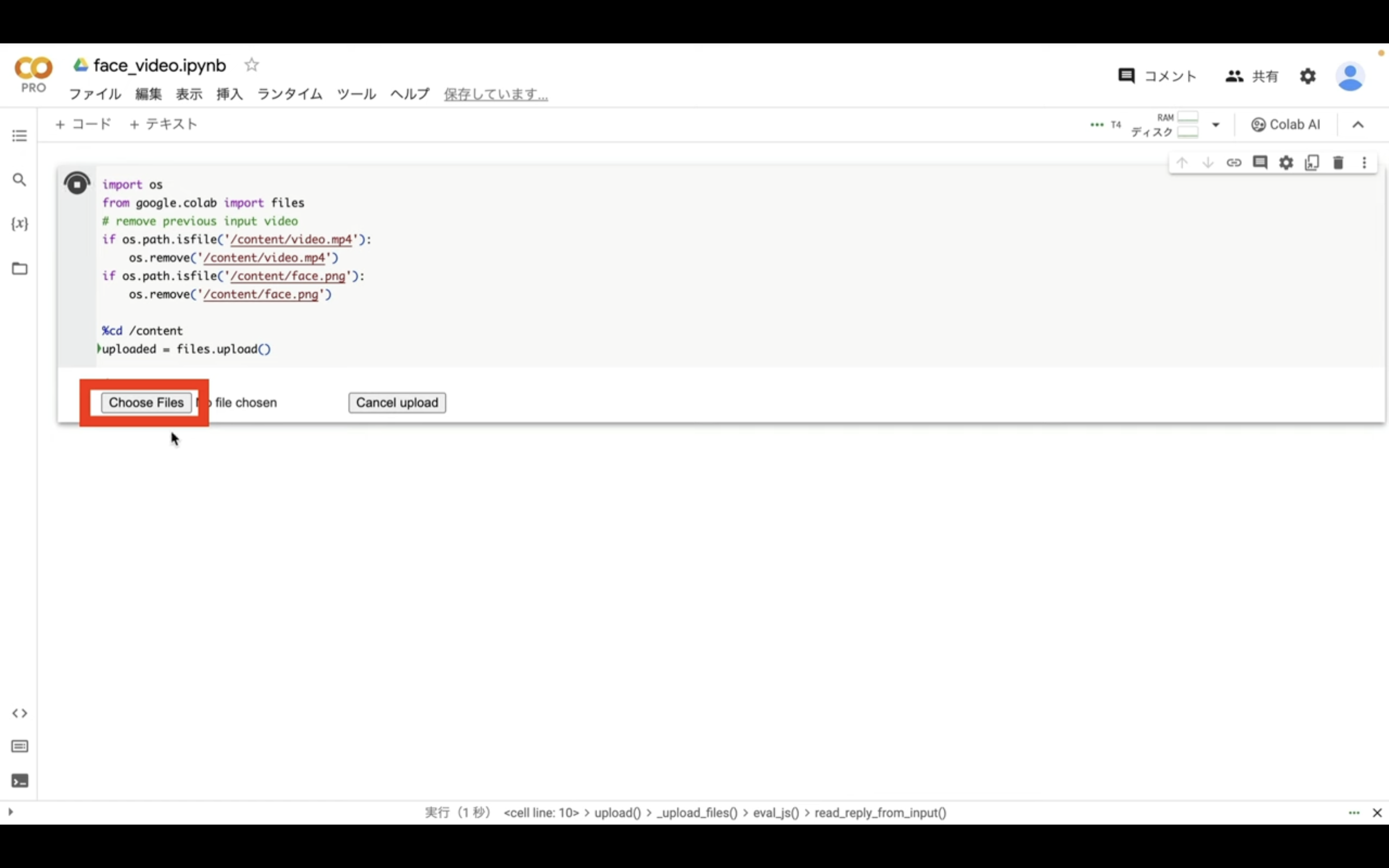
このボタンをクリックしてファイルをアップロードします。
「video.mp4」はこちらを使用しました。
「face.png」はこちらを使用しました。

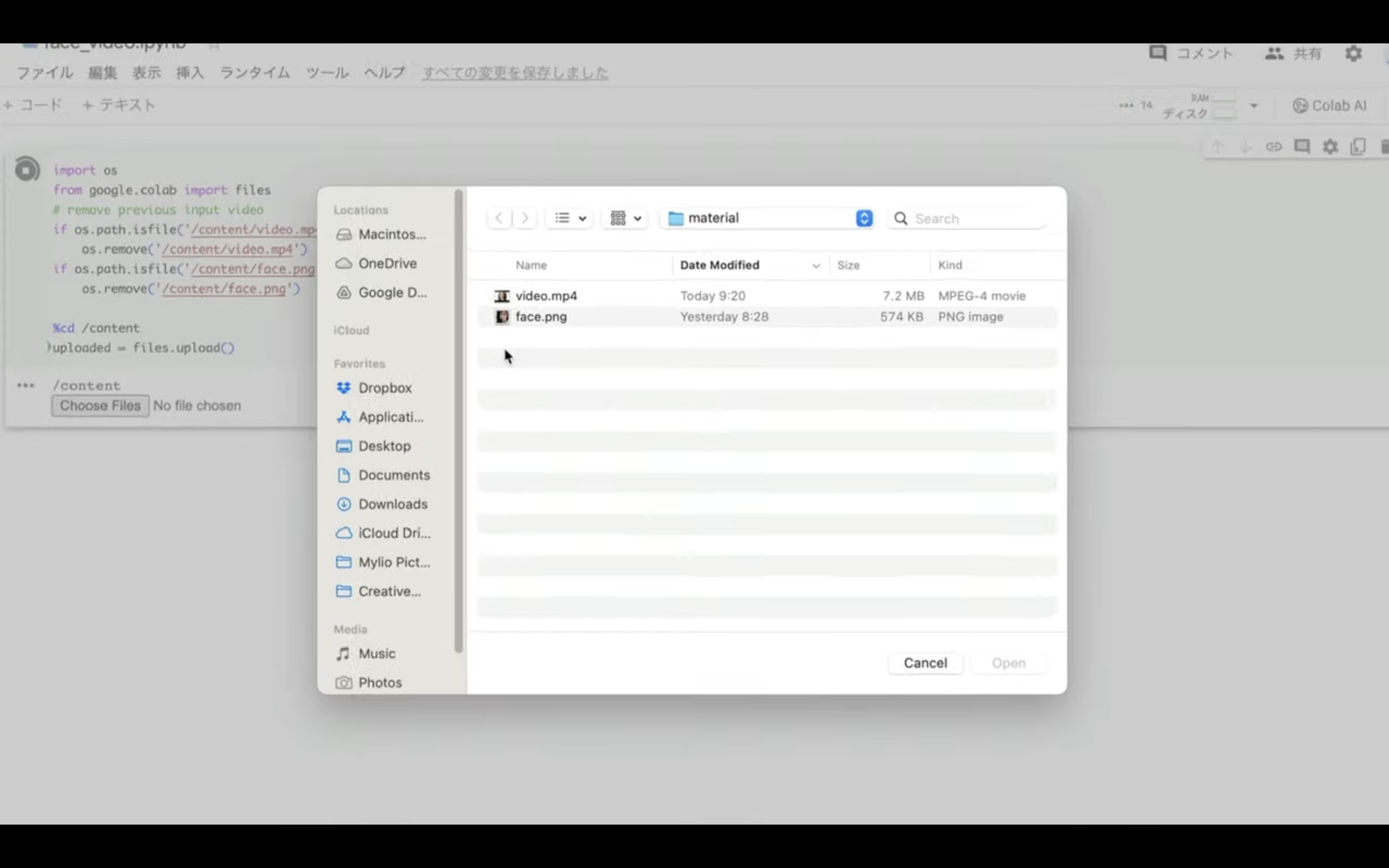
アップロードするファイルの名前は必ず「face.png」と「video.mp4」にしておきます。
これ以外のファイル名だとエラーになりますのでご注意ください。
ファイルを選択してアップロードを開始します。
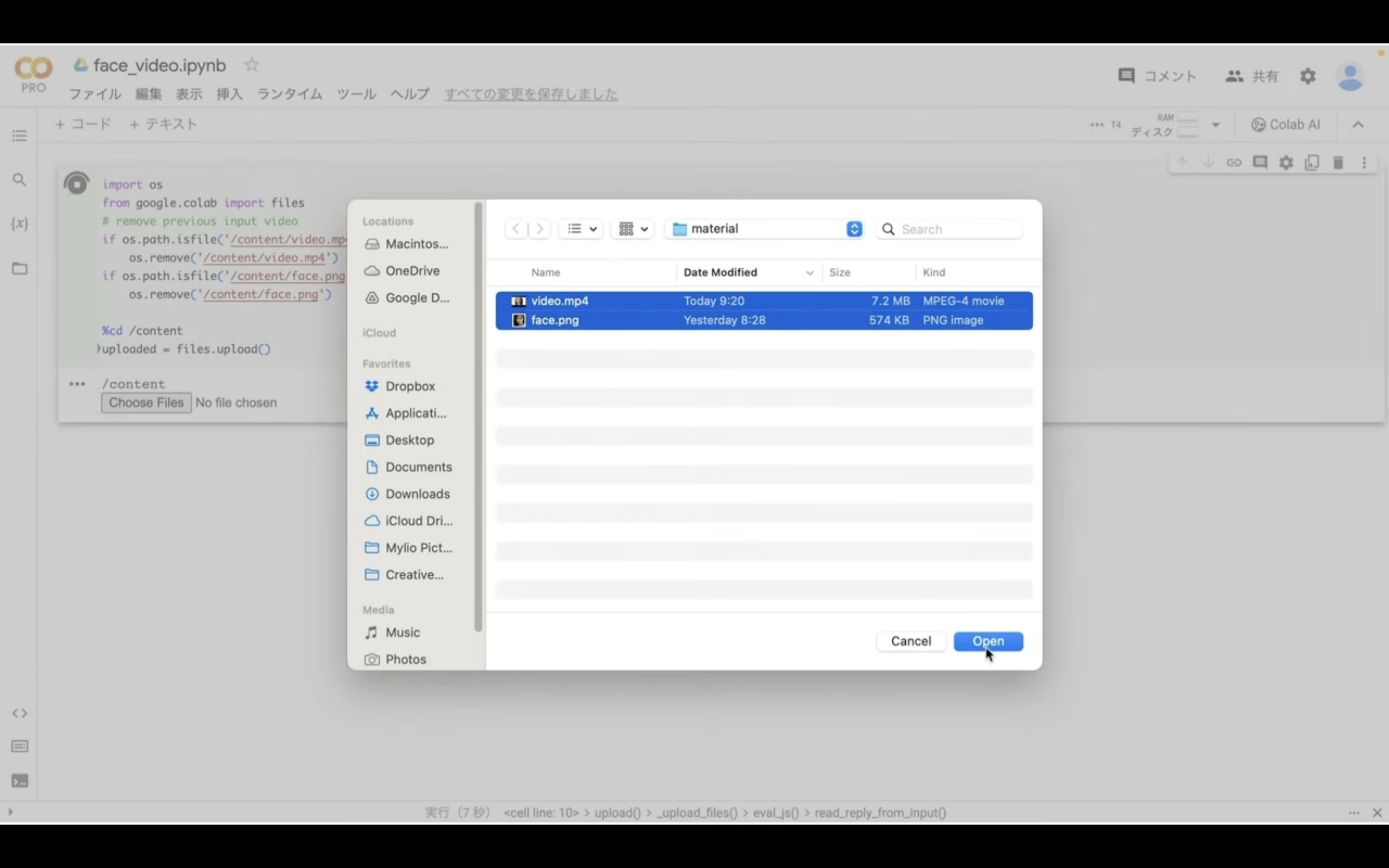
ファイルが アップロードされるまでしばらく待ちます。
これで1枚の顔写真と表情を変えている動画のアップロードが完了しました。
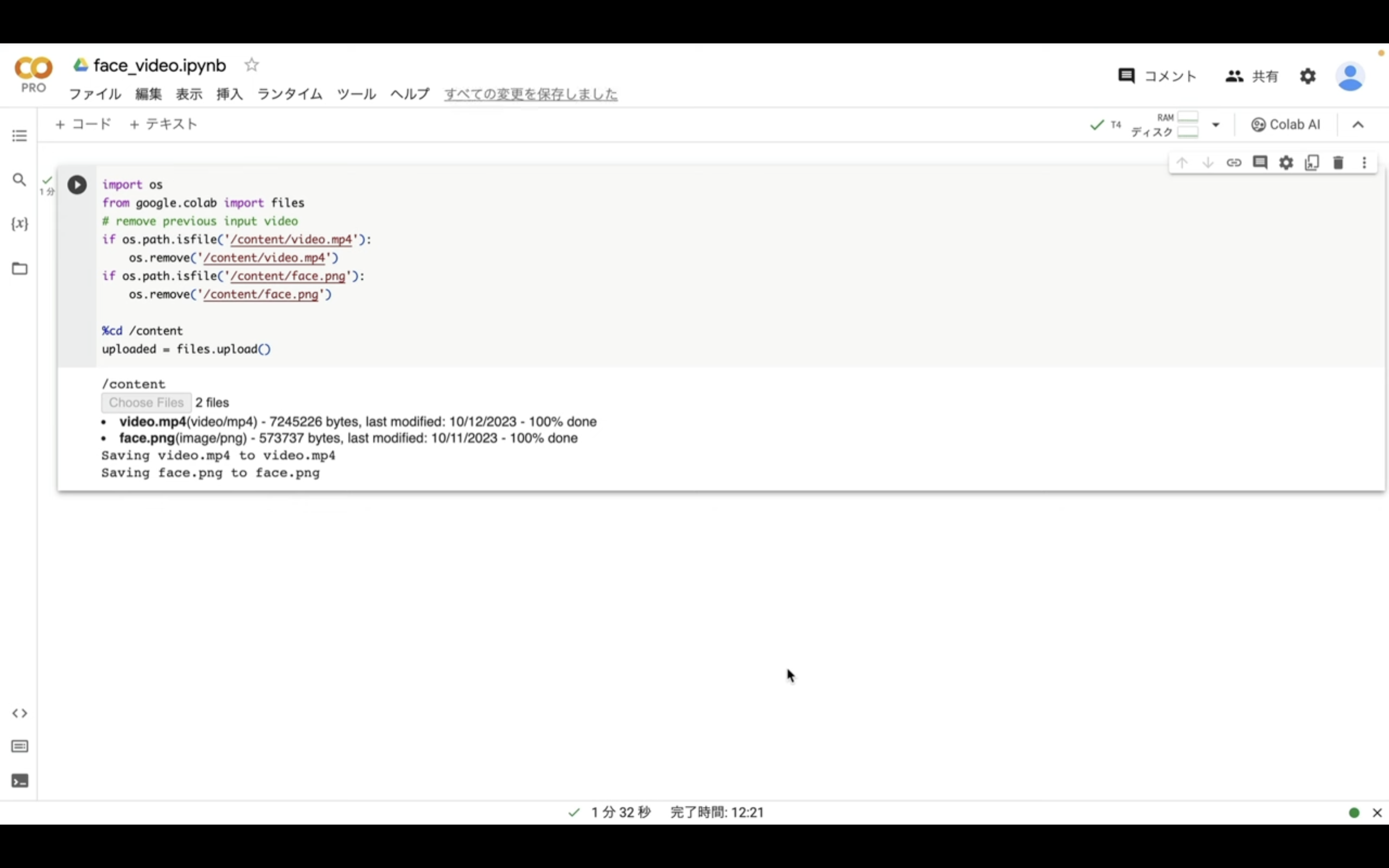
それでは早速動画を生成していきましょう。
以下のテキストをコピーします。
# ライブラリのインポート
import os
import imageio
import imageio_ffmpeg
import numpy as np
import matplotlib.pyplot as plt
import warnings
from skimage.transform import resize
from IPython.display import HTML
from google.colab import files
from base64 import b64encode
import moviepy.editor as mp
import torch
from skimage import img_as_ubyte
warnings.filterwarnings("ignore")
def get_video_resolution(video_path):
"""Function to get the resolution of a video"""
import cv2
video = cv2.VideoCapture(video_path)
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
return (width, height)
def resize_video(video_path, new_resolution):
"""Function to resize a video"""
import cv2
video = cv2.VideoCapture(video_path)
fourcc = int(video.get(cv2.CAP_PROP_FOURCC))
fps = video.get(cv2.CAP_PROP_FPS)
width, height = new_resolution
output_path = os.path.splitext(video_path)[0] + '_720p.mp4'
writer = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
while True:
success, frame = video.read()
if not success:
break
resized_frame = cv2.resize(frame, new_resolution)
writer.write(resized_frame)
video.release()
writer.release()
# ライブラリのインストールとリポジトリのクローン
!git clone https://github.com/splendormagic/Thin-Plate-Spline-Motion-Model
!pip install face_alignment imageio_ffmpeg
# ディレクトリとチェックポイントの設定
%cd Thin-Plate-Spline-Motion-Model
!mkdir -p checkpoints
%cd checkpoints
!gdown --id 16EXucOHzv8jQzwO8mBNR8eDfdSqBhBhK
%cd ..
from demo import load_checkpoints, make_animation
# 設定パラメータ
device = torch.device('cuda:0')
dataset_name = 'vox'
source_image_path = '/content/face.png'
driving_video_path = '/content/video.mp4'
output_video_path = './generated.mp4'
config_path = 'config/vox-256.yaml'
checkpoint_path = 'checkpoints/vox.pth.tar'
predict_mode = 'relative'
find_best_frame = False
pixel = 384 if dataset_name == 'ted' else 256
# 画像とビデオの読み込み
source_image = imageio.imread(source_image_path)
source_image = resize(source_image, (pixel, pixel))[..., :3]
reader = imageio.get_reader(driving_video_path)
fps = reader.get_meta_data()['fps']
driving_video = [resize(frame, (pixel, pixel))[..., :3] for frame in reader]
reader.close()
# モデルのロード
inpainting, kp_detector, dense_motion_network, avd_network = load_checkpoints(config_path=config_path, checkpoint_path=checkpoint_path, device=device)
# アニメーションの作成
if predict_mode == 'relative' and find_best_frame:
from demo import find_best_frame as _find
i = _find(source_image, driving_video, device.type == 'cpu')
print("Best frame:", i)
driving_forward = driving_video[i:]
driving_backward = driving_video[:(i + 1)][::-1]
predictions_forward = make_animation(source_image, driving_forward, inpainting, kp_detector, dense_motion_network, avd_network, device=device, mode=predict_mode)
predictions_backward = make_animation(source_image, driving_backward, inpainting, kp_detector, dense_motion_network, avd_network, device=device, mode=predict_mode)
predictions = predictions_backward[::-1] + predictions_forward[1:]
else:
predictions = make_animation(source_image, driving_video, inpainting, kp_detector, dense_motion_network, avd_network, device=device, mode=predict_mode)
# 結果の保存とダウンロード
imageio.mimsave(output_video_path, [img_as_ubyte(frame) for frame in predictions], fps=fps)
files.download(output_video_path)
テキストをコピーしたらGoogleコラボの画面に戻ります。
コードと書かれているテキストをクリックしてテキストボックスを追加します。
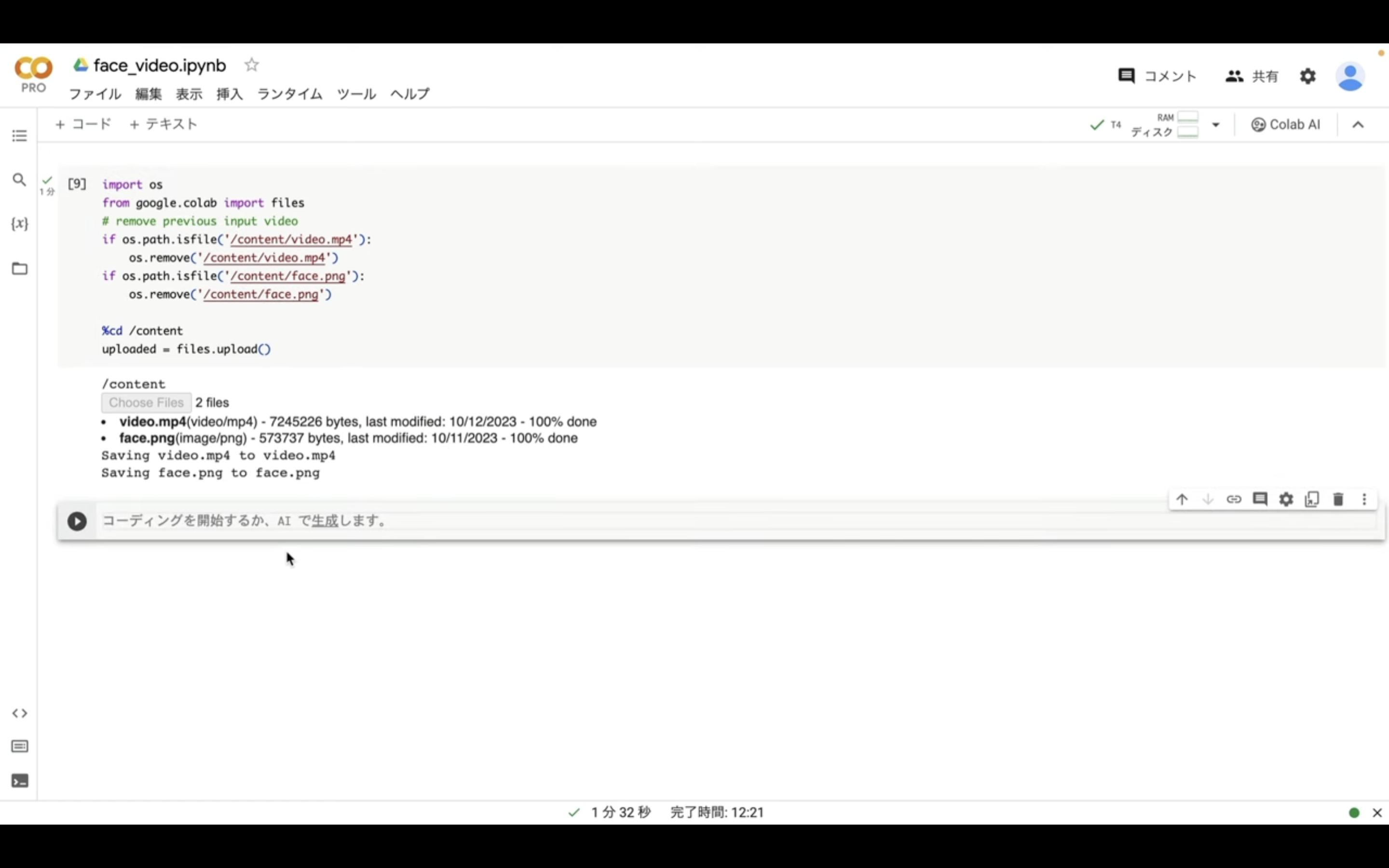
テキストボックスが追加されたら先ほどコピーしたテキストを貼り付けます。
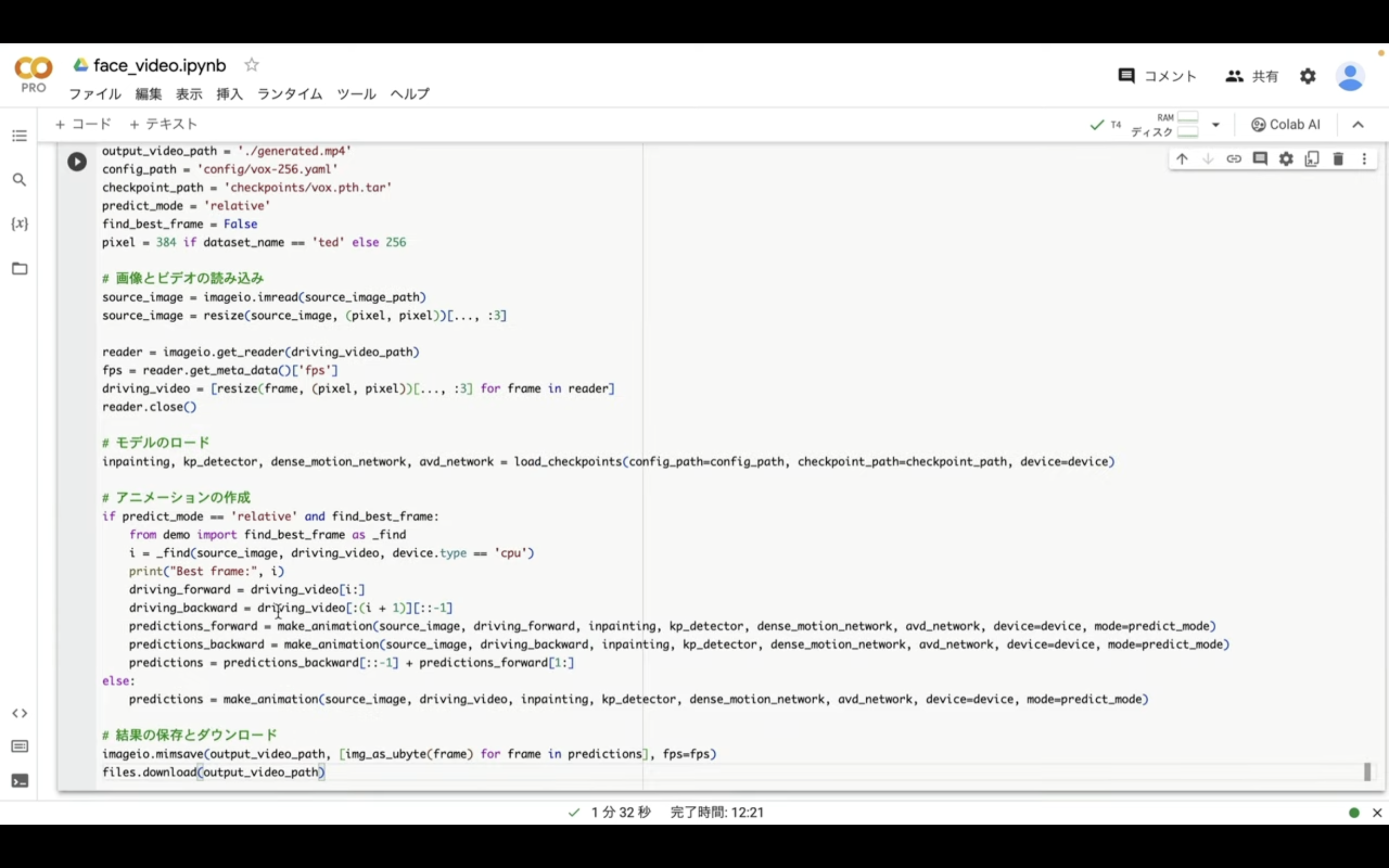
これで動画を生成するための準備が整いました。
これを読めば誰でも簡単にクオリティーの高いAI美女が作れるようになっているので興味がある人は、下のバナーをクリックして購入してみてね🎶
それでは早速動画を生成していきましょう。
左上にある再生ボタンをクリックします。
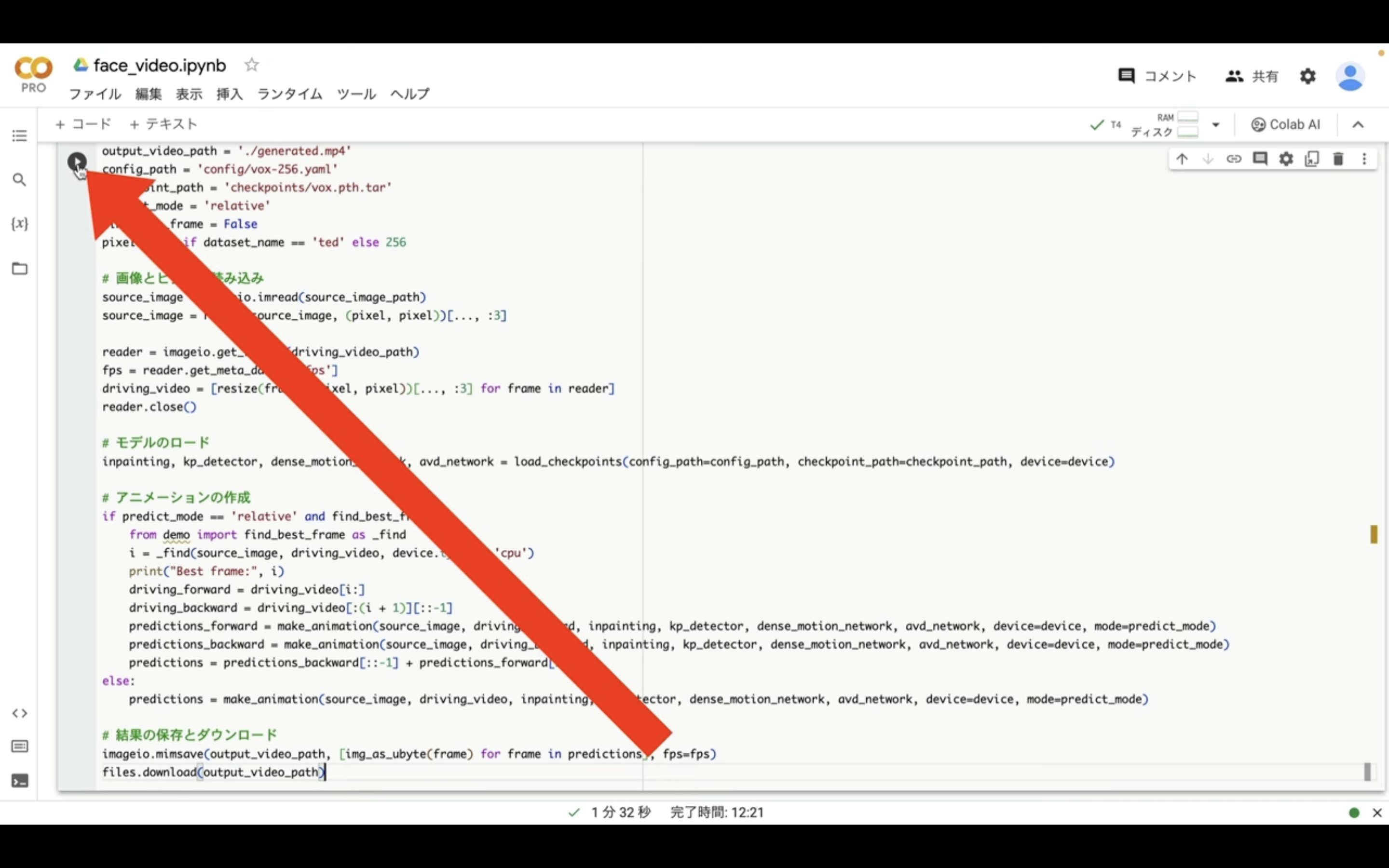
そうすると動画の生成が開始されます。
生成された動画は自動的にダウンロードされるように設定されています。
是非皆さんも試してみてくださいね🎵






