

▶︎動画でも話してるので、文章読むのが面倒な方はこちらをみてもらえればと思います。
今回は複数のディープフェイクの画像を一括で作成する方法について解説します。

これを読めば誰でも簡単にクオリティーの高いAI美女が作れるようになっているので興味がある人は、下のバナーをクリックして購入してみてね🎶

元になる画像が複数のものに対して1枚の指定画像をもとに複数のディープフェイクの画像を生成する方法
今回のディープフェイクの画像を生成するためには、「Ghost」という公開されているソースコードを利用します。
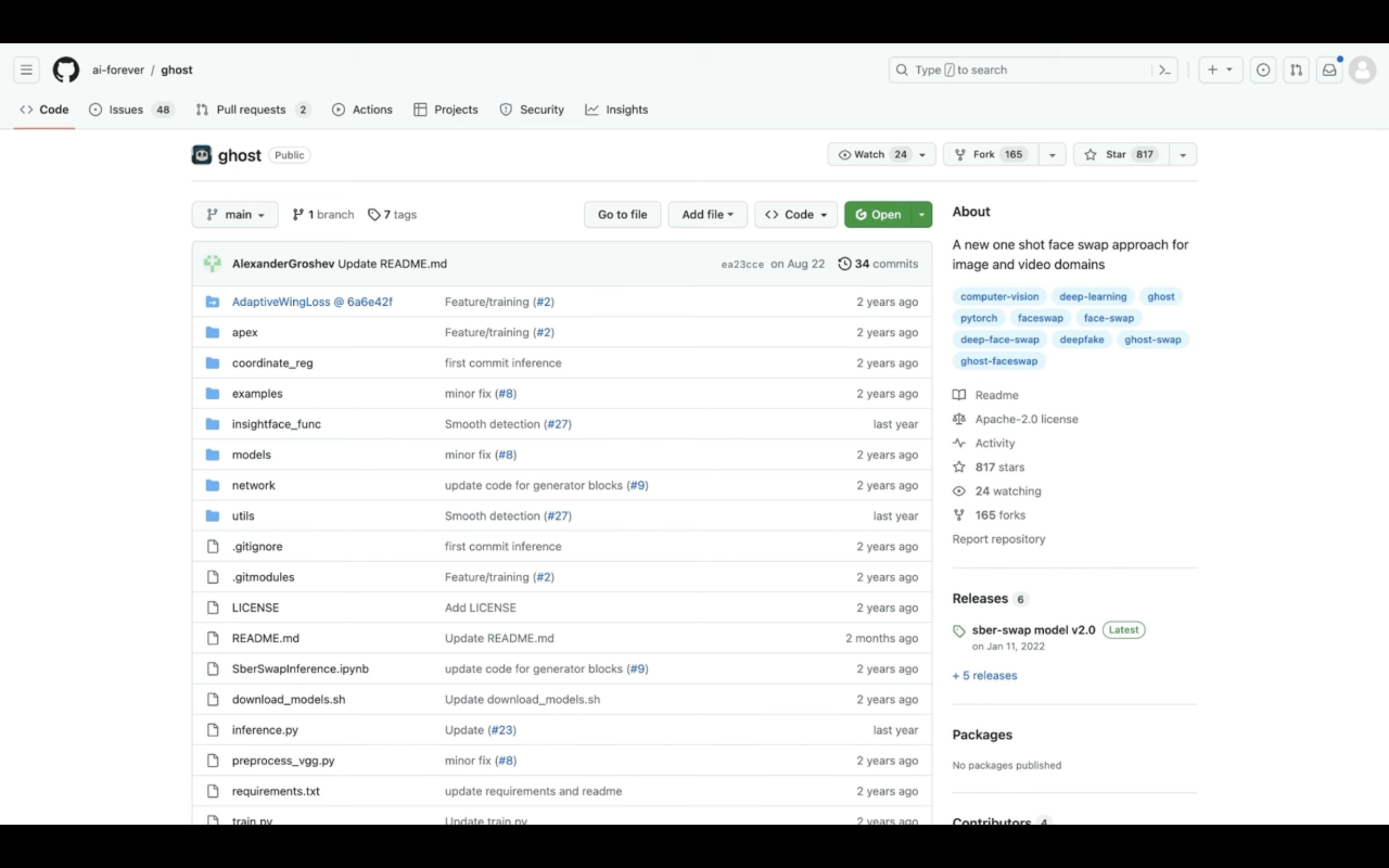
ソースコードが公開されているページへのリンクは、以下に貼っておきますのでそちらをご確認ください。
この動画では、このソースコードを実行するためにGoogleコラボを利用します。
Googleコラボはクラウド上でプログラミングを実行することができるGoogleが提供しているツールです。
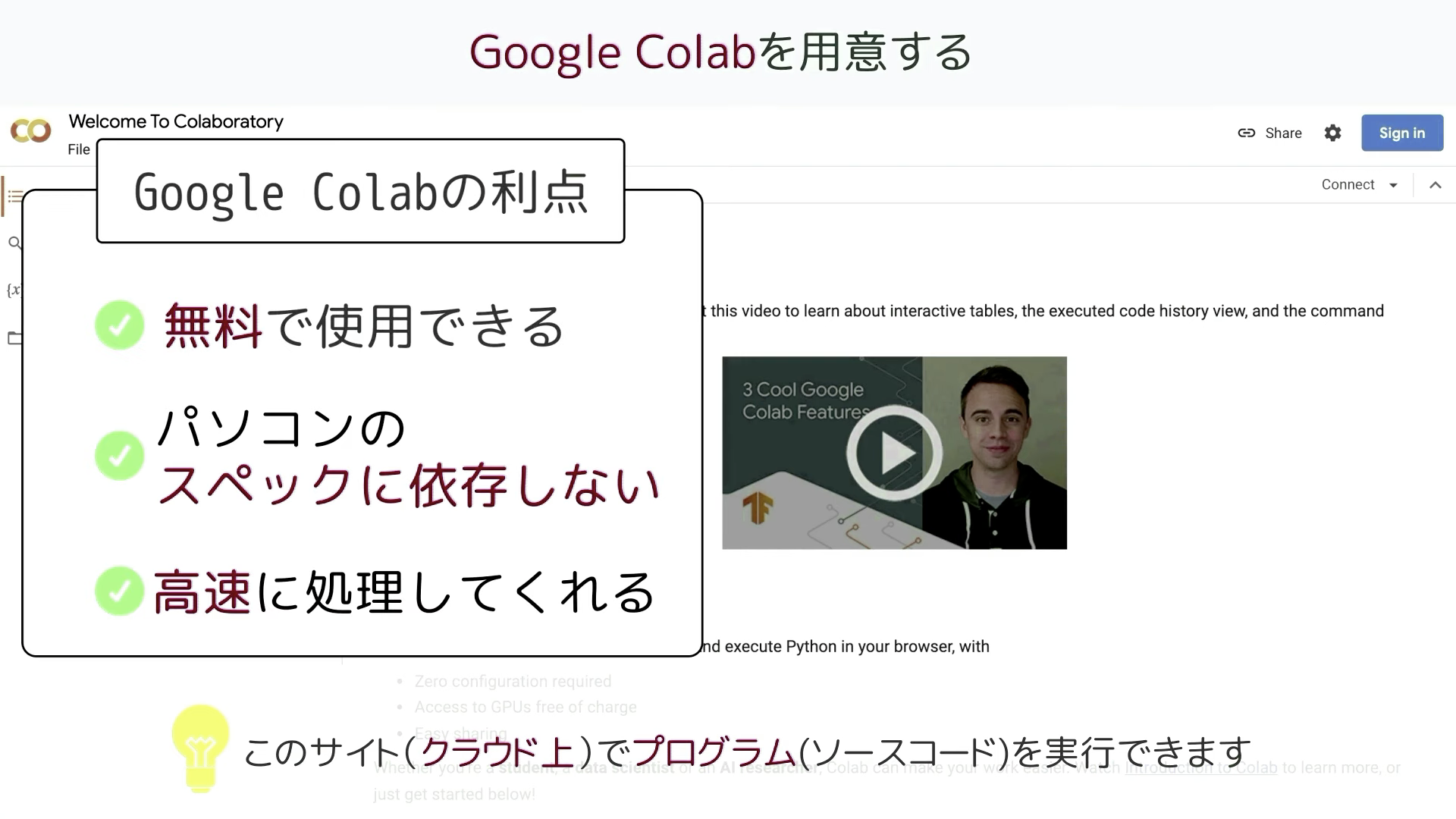
無料で使用することができ、自分のパソコンのスペックに依存せず高速な処理を行うことができるのが大きな利点です。
Googleアカウントを持っていれば、誰でもGoogleコラボを使用することができます。
Googleコラボのサイトにアクセスしたら、このような画面が表示されると思います。
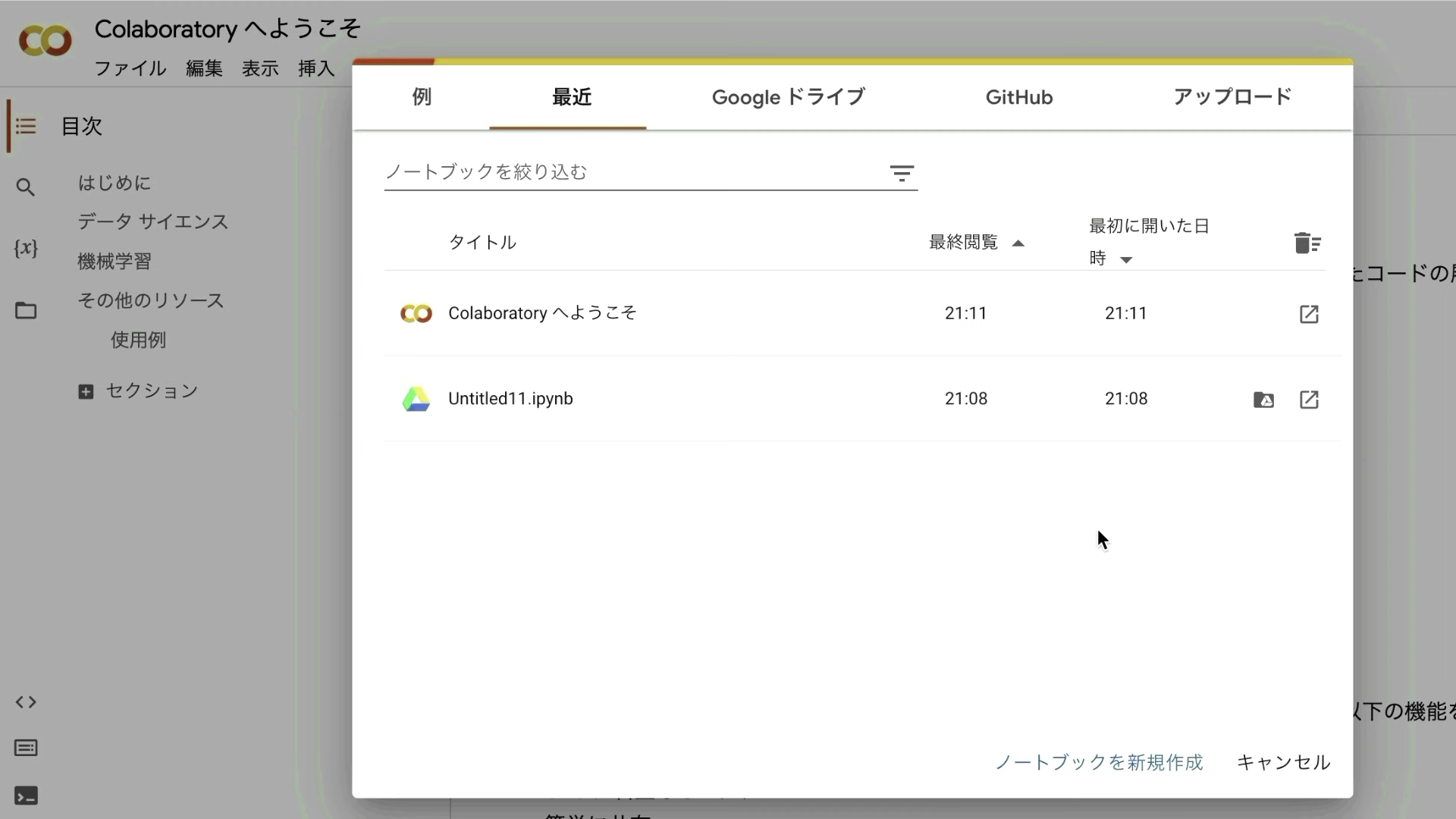
表示されているポップアップ画面の右下にある「ノートブックを新規作成」と書かれているテキストをクリックします。
次に「ランタイム」のボタンをクリックし、「ランタイムのタイプを変更」をクリックします。
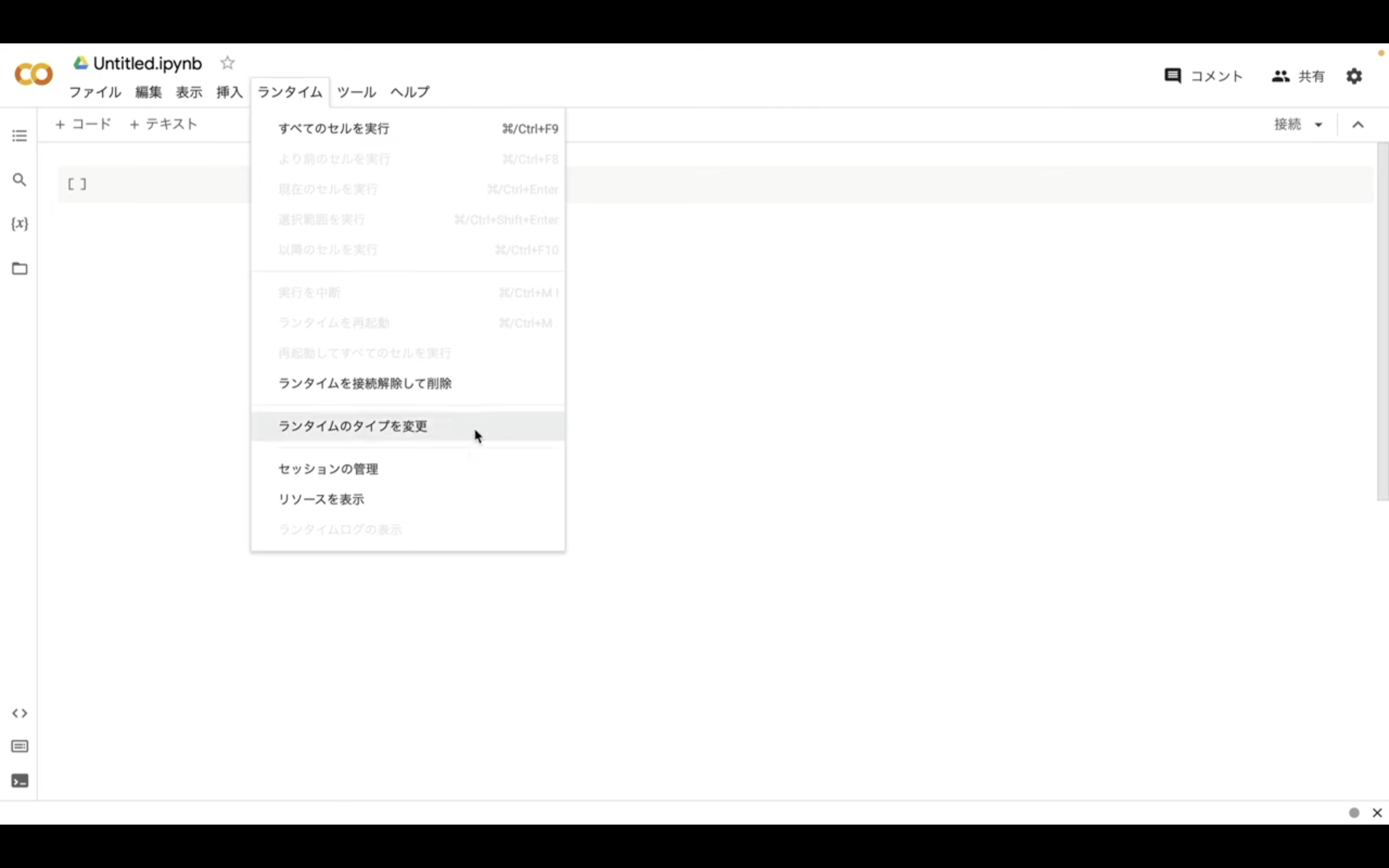
ランタイムのタイプはPython3のままで大丈夫です。
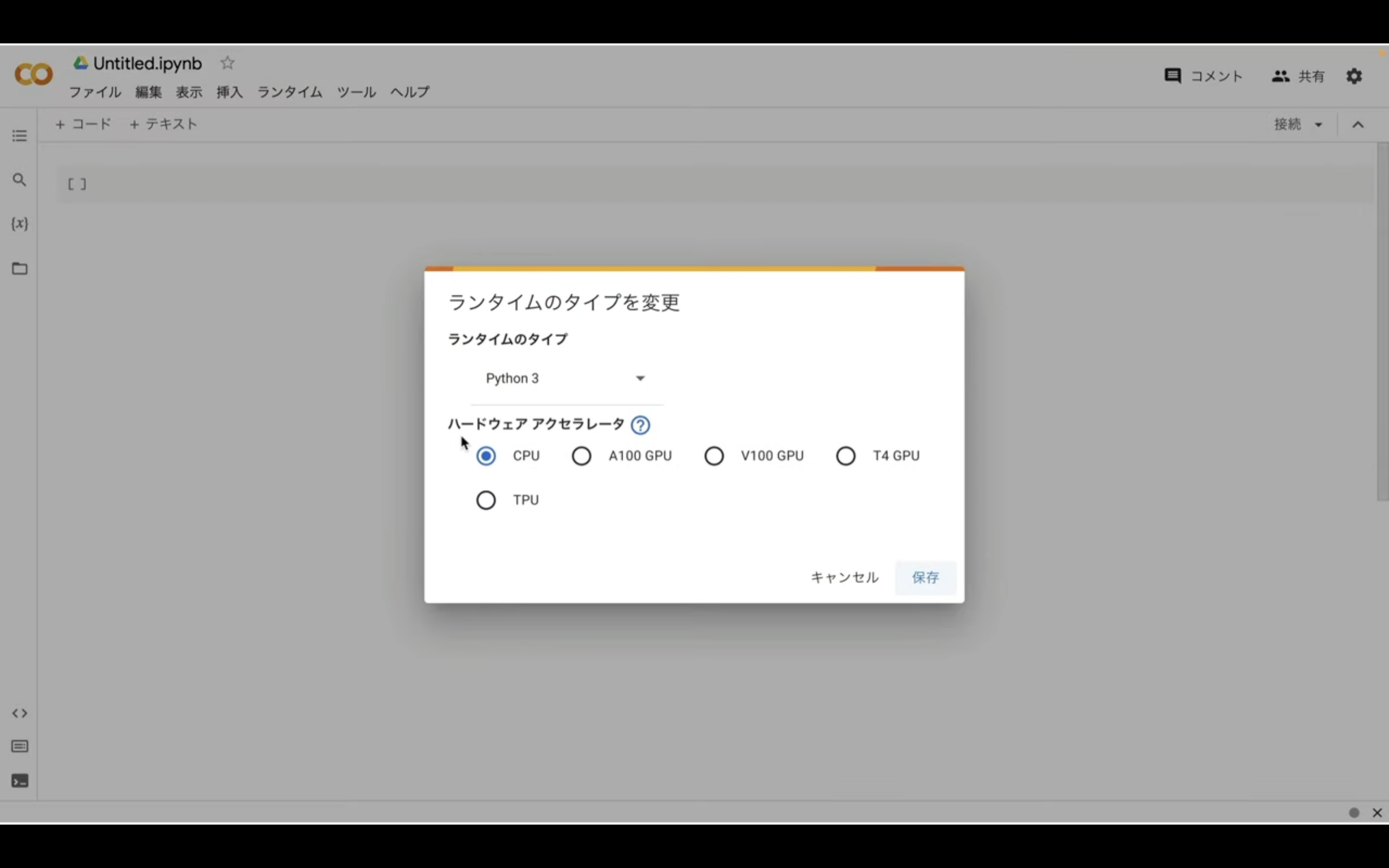
ハードウェアアクセラレーターはT4 GPUを選択しておきましょう。
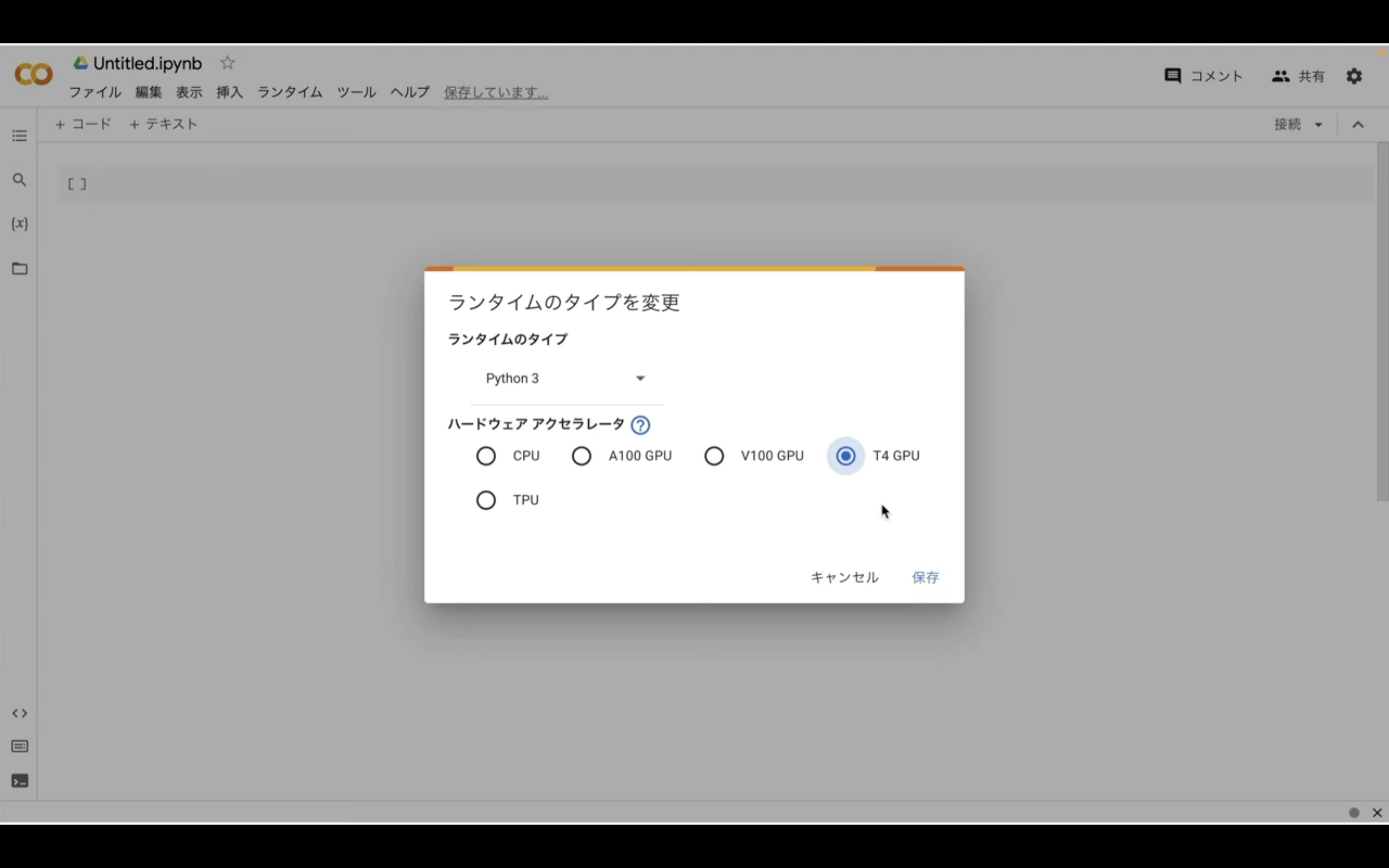
ノートブックの設定を指定したら右下の保存ボタンをクリックします。
これでGoogleコラボで「Ghost」を実行するための準備が整いました。
先ほどGoogleコラボは無料で利用できると説明しましたが、無料版だとリソースの割り当てが保証されていません。
そのため、強制的にコードを終了されてしまうことがあります。
最近はGoogleコラボを利用するユーザーが増えていますので、無料版に割り当てられるGoogleコラボのリソースが減ってしまっています。
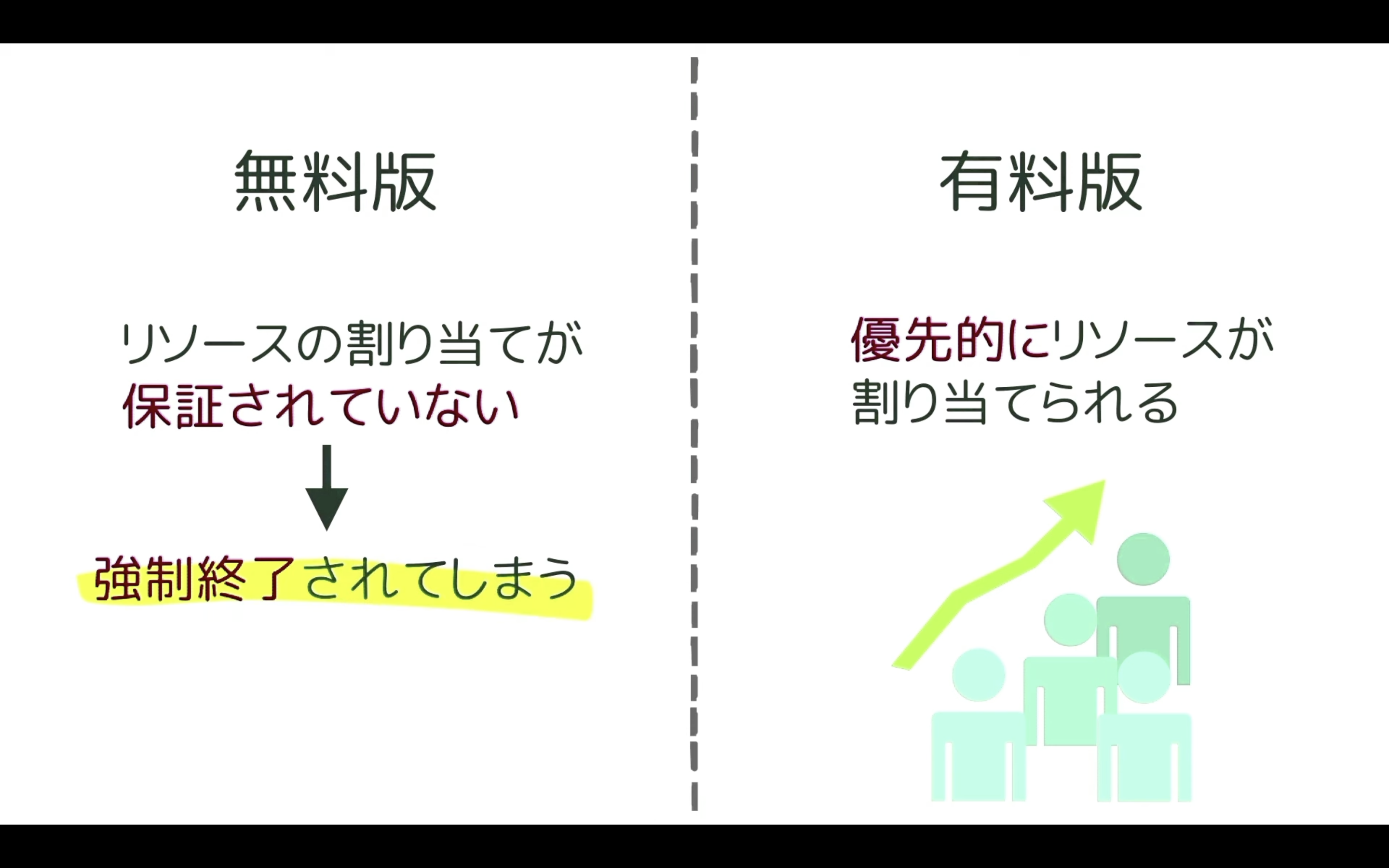
その結果、無料版では以前より実行中のコードが強制終了されてしまうことが多くなってきました。
具体的には、コードの実行が強制的に終了された場合は、このような画面になります。
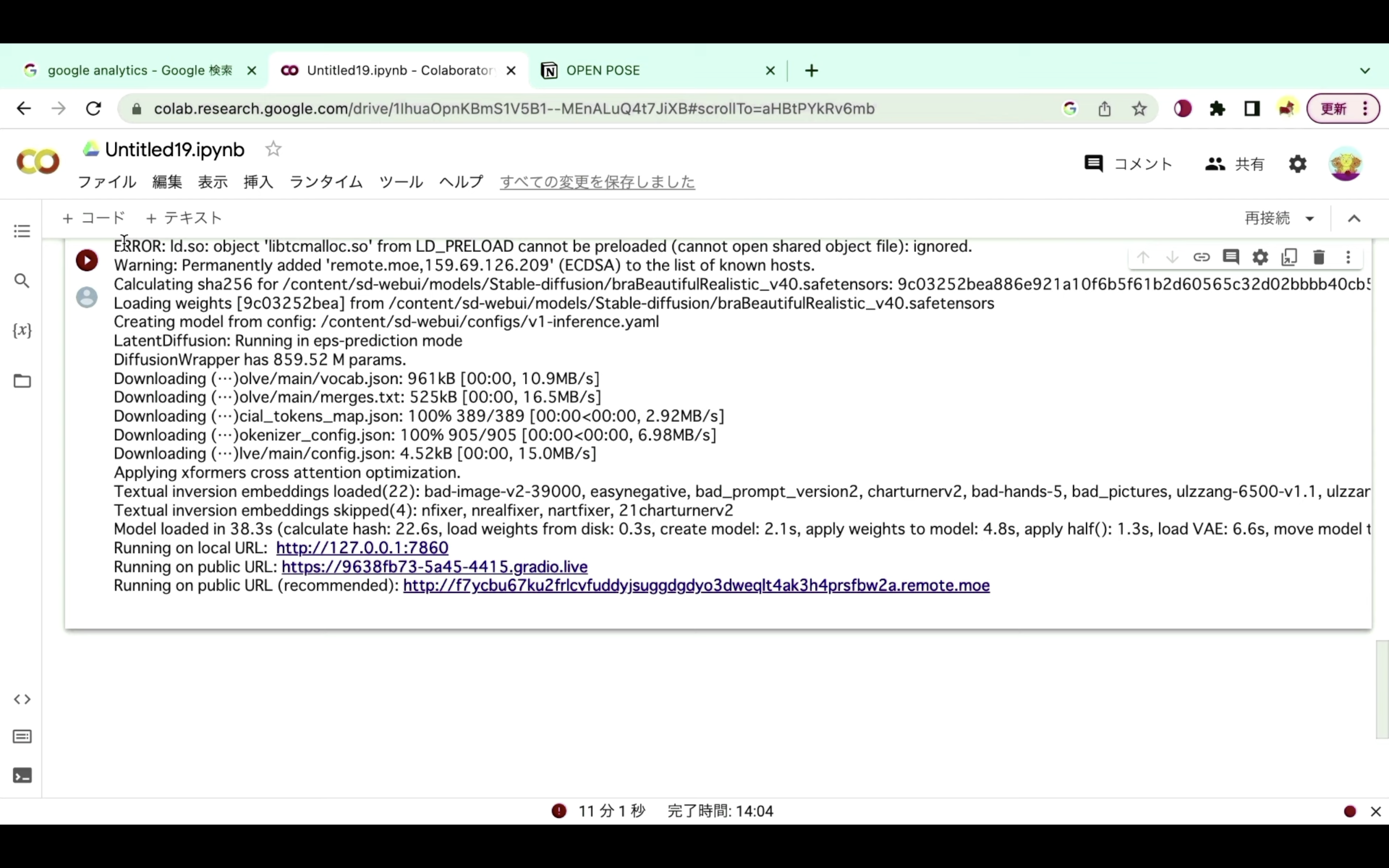
再生ボタンの部分が赤くなっている、もしくは赤いビックリマークのアイコンが表示されているこのような場合は、コードが強制的に中断されたと判断していいと思います。
強制的に中断されてしまう状況が続くようであれば、有料プランへの切り替えをおすすめします。
有料プランへの切り替え方法については詳細を解説している動画を以下のリンクに貼っておきますので、そちらをご確認ください。
なお、ここからは有料版に切り替えた状態で解説を進めます。
有料版に切り替えた状態で解説
Googleコラボの準備が整ったら、以下に貼ってあるテキストをコピーします。
# ----------------------------------------------------------------
# 1. GitHubをクローンしてモデルをダウンロード
# ----------------------------------------------------------------
!git clone https://github.com/sberbank-ai/sber-swap.git
%cd sber-swap
# arcfaceをロード
!wget -P ./arcface_model https://github.com/sberbank-ai/sber-swap/releases/download/arcface/backbone.pth
!wget -P ./arcface_model https://github.com/sberbank-ai/sber-swap/releases/download/arcface/iresnet.py
# 顔の特徴点検出器をロード
!wget -P ./insightface_func/models/antelope https://github.com/sberbank-ai/sber-swap/releases/download/antelope/glintr100.onnx
!wget -P ./insightface_func/models/antelope https://github.com/sberbank-ai/sber-swap/releases/download/antelope/scrfd_10g_bnkps.onnx
# モデル自体をロード
!wget -P ./weights https://github.com/sberbank-ai/sber-swap/releases/download/sber-swap-v2.0/G_unet_2blocks.pth
# 高画質モデルをロード
!wget -P ./weights https://github.com/sberbank-ai/sber-swap/releases/download/super-res/10_net_G.pth
# ----------------------------------------------------------------
# 2. 必要なライブラリをインストール
# ----------------------------------------------------------------
!pip install mxnet-cu112
!pip install onnxruntime-gpu==1.12
!pip install insightface==0.2.1
!pip install kornia==0.5.4
!pip install dill
!rm /usr/local/lib/python3.10/dist-packages/insightface/model_zoo/model_zoo.py #pythonのバージョンが異なる場合は、パスを変更してください
!wget -P /usr/local/lib/python3.10/dist-packages/insightface/model_zoo/ https://github.com/AlexanderGroshev/insightface/releases/download/model_zoo/model_zoo.py #pythonのバージョンが異なる場合は、パスを変更してください
# ----------------------------------------------------------------
# 3. 準備
# ----------------------------------------------------------------
import cv2
import torch
import time
import os
from utils.inference.image_processing import crop_face, get_final_image, show_images
from utils.inference.video_processing import read_video, get_target, get_final_video, add_audio_from_another_video, face_enhancement
from utils.inference.core import model_inference
from network.AEI_Net import AEI_Net
from coordinate_reg.image_infer import Handler
from insightface_func.face_detect_crop_multi import Face_detect_crop
from arcface_model.iresnet import iresnet100
from models.pix2pix_model import Pix2PixModel
from models.config_sr import TestOptions
import warnings
warnings.filterwarnings("ignore")
# ----------------------------------------------------------------
# 4. モデルを初期化
# ----------------------------------------------------------------
app = Face_detect_crop(name='antelope', root='./insightface_func/models')
app.prepare(ctx_id= 0, det_thresh=0.6, det_size=(640,640))
# 顔生成のメインモデル
G = AEI_Net(backbone='unet', num_blocks=2, c_id=512)
G.eval()
G.load_state_dict(torch.load('weights/G_unet_2blocks.pth', map_location=torch.device('cpu')))
G = G.cuda()
G = G.half()
# 顔の埋め込みを取得するためのarcfaceモデル
netArc = iresnet100(fp16=False)
netArc.load_state_dict(torch.load('arcface_model/backbone.pth'))
netArc=netArc.cuda()
netArc.eval()
# 顔の顔の特徴点を取得するモデル
handler = Handler('./coordinate_reg/model/2d106det', 0, ctx_id=0, det_size=640)
# 顔の高画質をするモデル、高画質を使用する場合はuse_sr=True、使用しない場合はuse_sr=False
use_sr = True
if use_sr:
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
torch.backends.cudnn.benchmark = True
opt = TestOptions()
model = Pix2PixModel(opt)
model.netG.train()
テキストをコピーしたらGoogleコラボの画面に戻ります。
そしてテキストボックスにコピーしたテキストを貼り付けます。
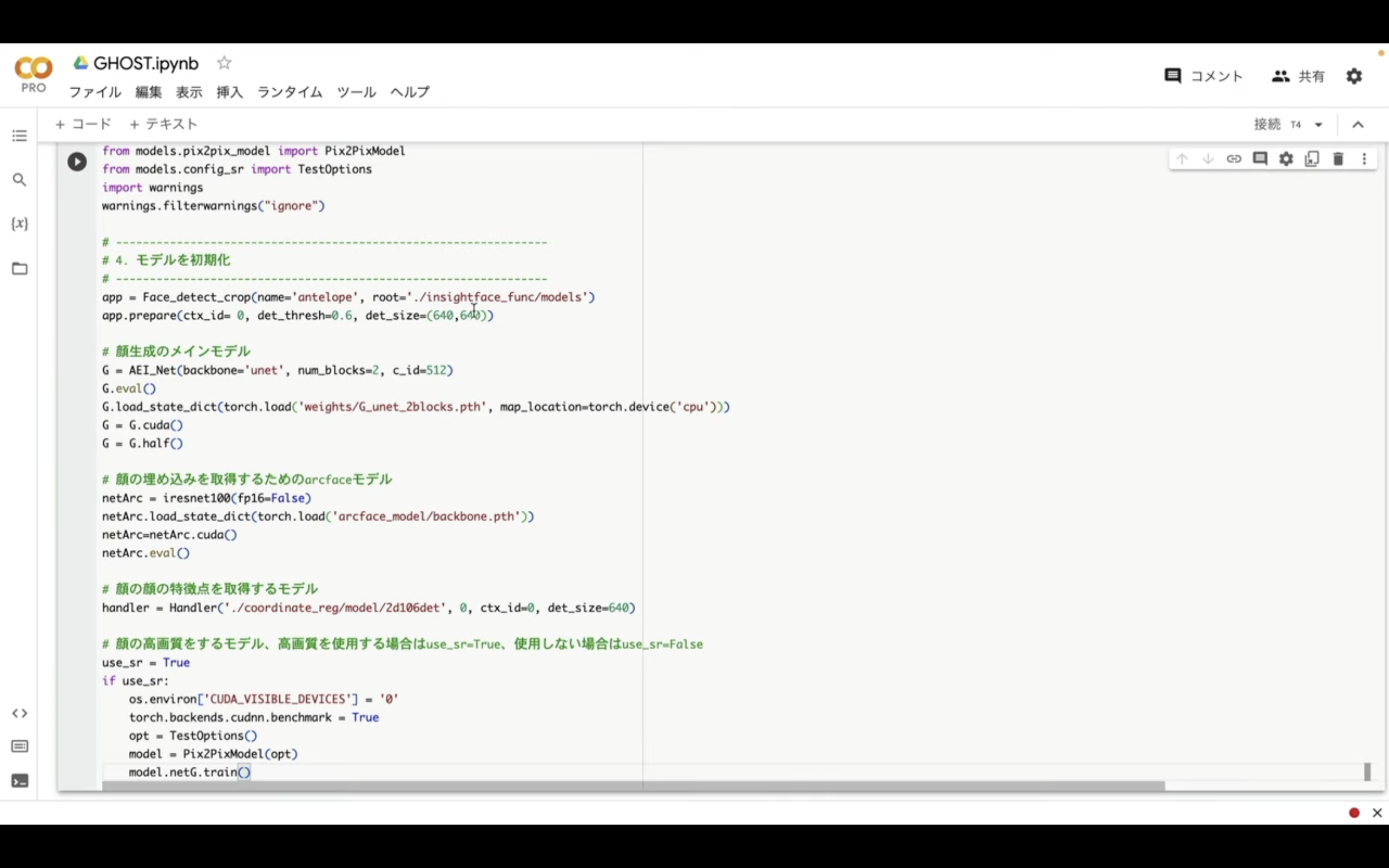
テキストを貼り付けたら左上の再生ボタンをクリックします。
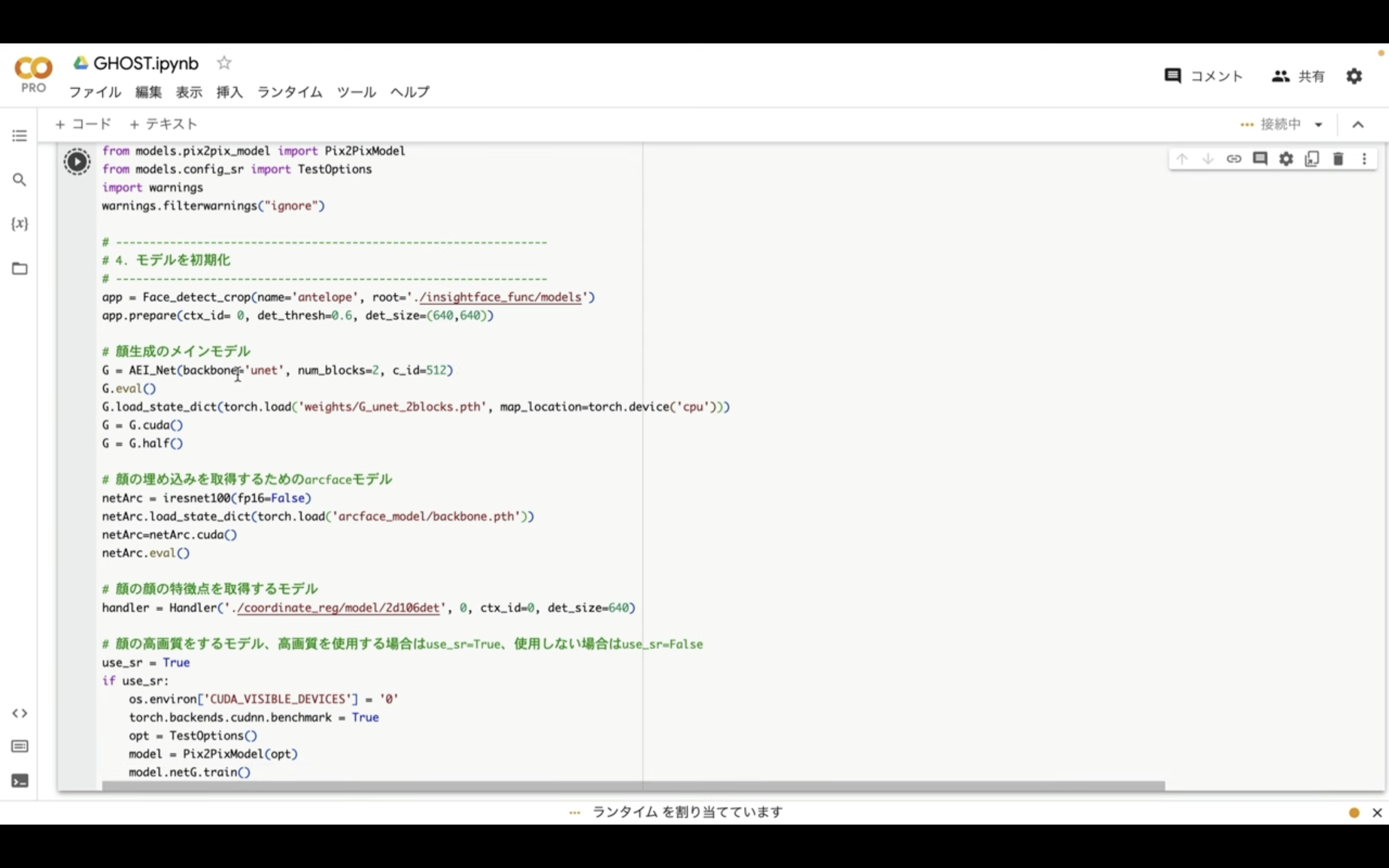
これで貼り付けたテキストが実行されます。
この処理には数分程度かかるので、しばらく待ちましょう。
再生ボタンの左側に緑色のチェックマークが表示されたら、処理は完了です。
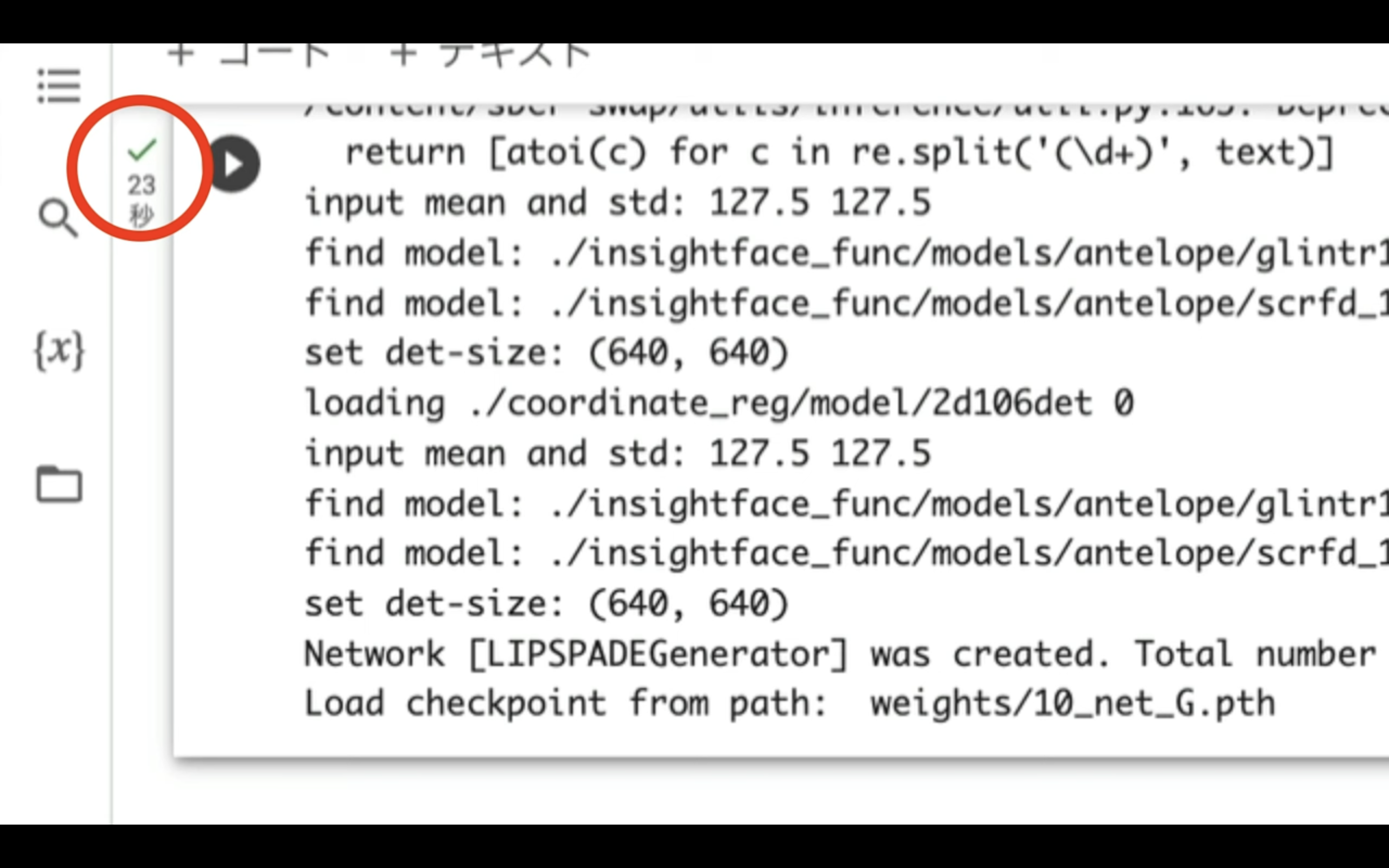
この処理が完了したら、以下に貼ってあるテキストをコピーします。
import glob
import os
from datetime import datetime
import subprocess
import shutil
# 現在の日時を "YYYYMMDD_HHMMSS" のフォーマットで取得
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# そのタイムスタンプを新しいディレクトリ名として使用
dest_dir = os.path.join("/content", timestamp)
# ディレクトリを作成
os.makedirs(dest_dir)
print(f"ディレクトリ'{dest_dir}'を作成しました。")
source_full = cv2.imread("/content/src.png")
source = crop_face(source_full, app, crop_size)[0]
source = [source[:, :, ::-1]]
# '/content/uploads/' ディレクトリ内の全ファイルを対象として処理
for target_path in glob.glob('/content/uploads/*'):
target_filename = os.path.basename(target_path)
target_full = cv2.imread(target_path)
full_frames = [target_full]
target = get_target(full_frames, app, crop_size)
batch_size = 120
START_TIME = time.time()
final_frames_list, crop_frames_list, full_frames, tfm_array_list = model_inference(full_frames,
source,
target,
netArc,
G,
app,
set_target = False,
crop_size=crop_size,
BS=batch_size)
if use_sr:
final_frames_list = face_enhancement(final_frames_list, model)
result = get_final_image(final_frames_list, crop_frames_list, full_frames[0], tfm_array_list, handler)
cv2.imwrite(f"{dest_dir}/{target_filename}", result)
# 作成したディレクトリをZIPに圧縮してダウンロード
shutil.make_archive(timestamp, 'zip', dest_dir)
files.download(f'{timestamp}.zip')テキストをコピーしたらGoogleコラボの画面に戻ります。
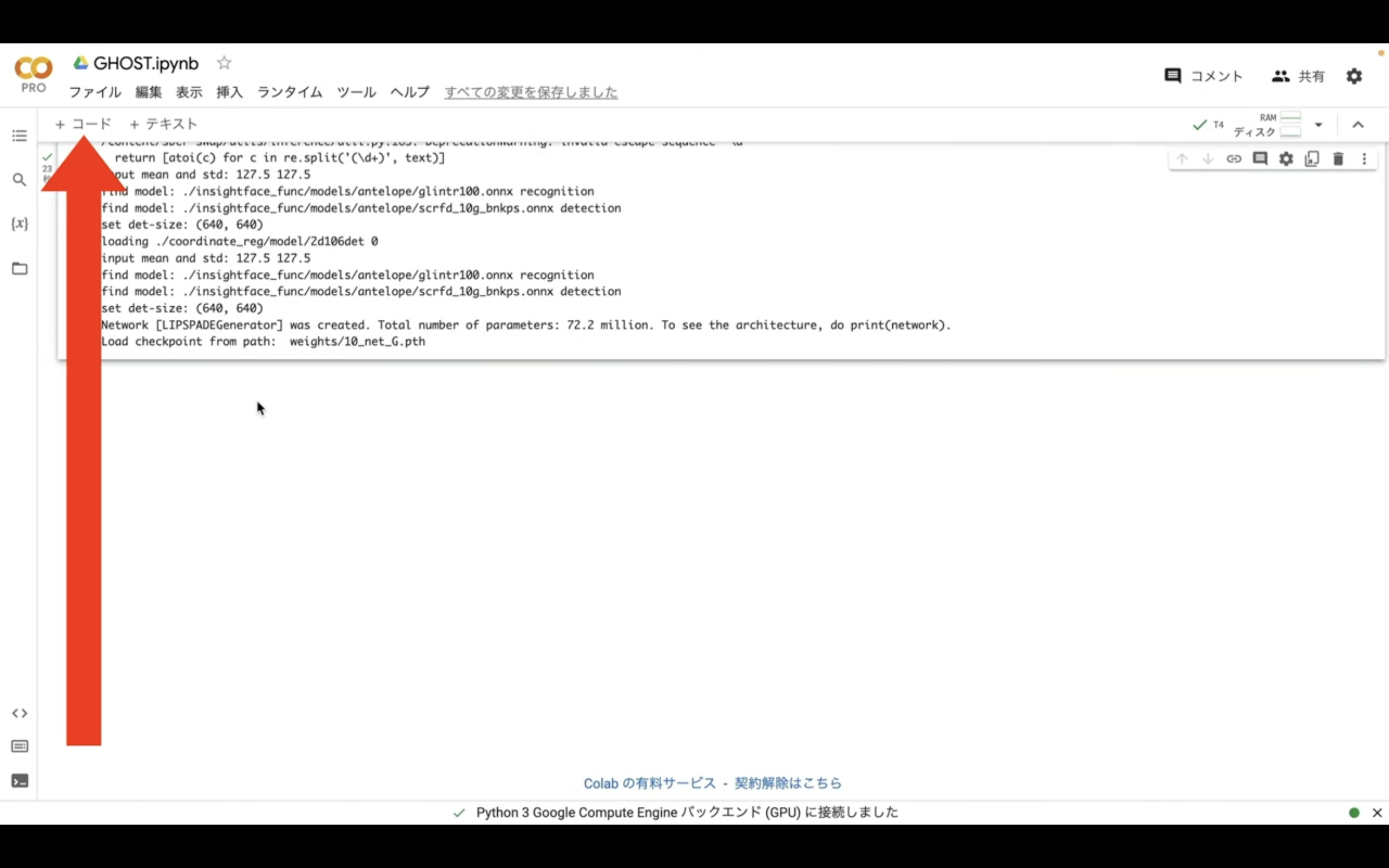
コードというテキストをクリックします。
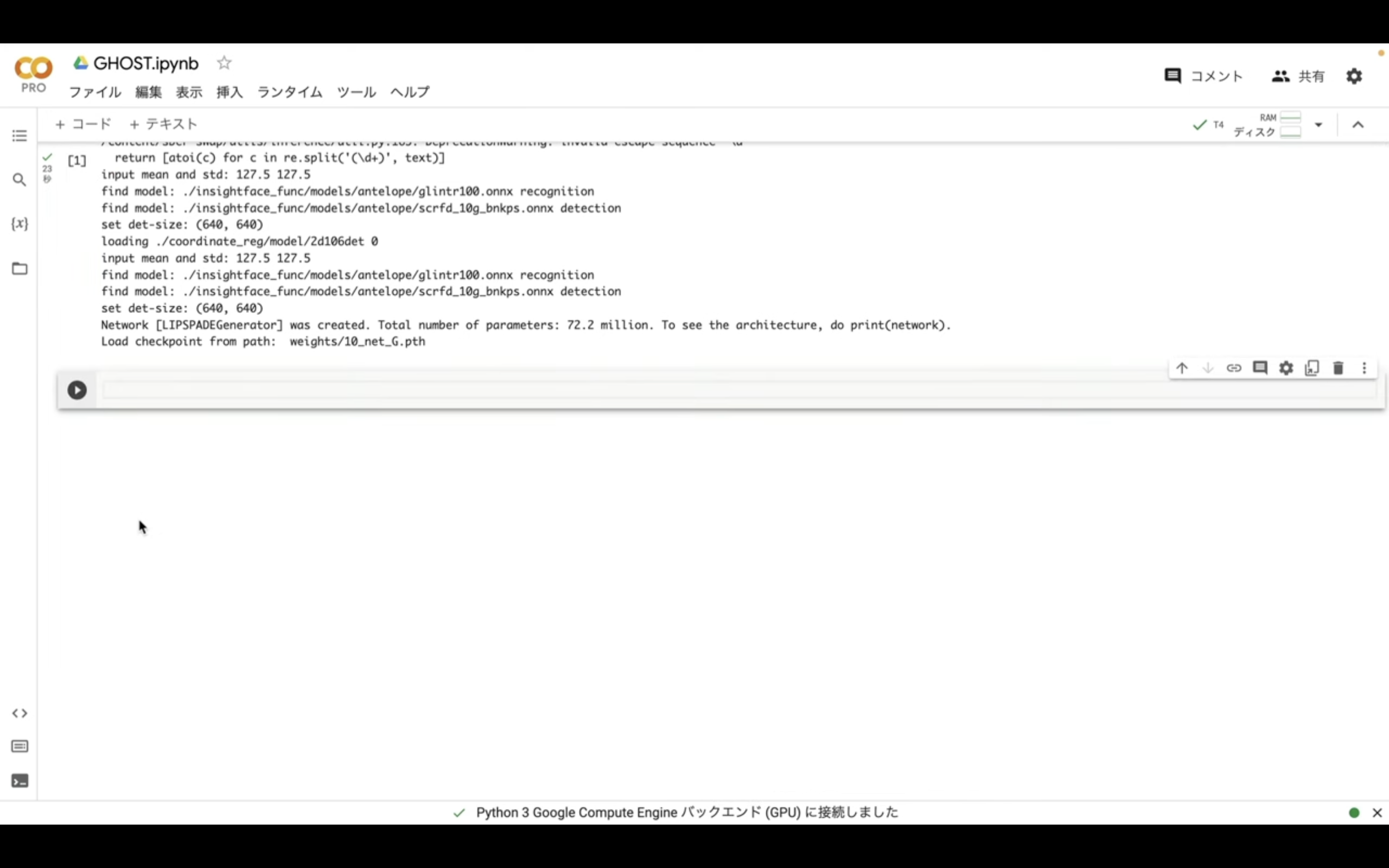
そうすると新しいテキストボックスが追加されます。
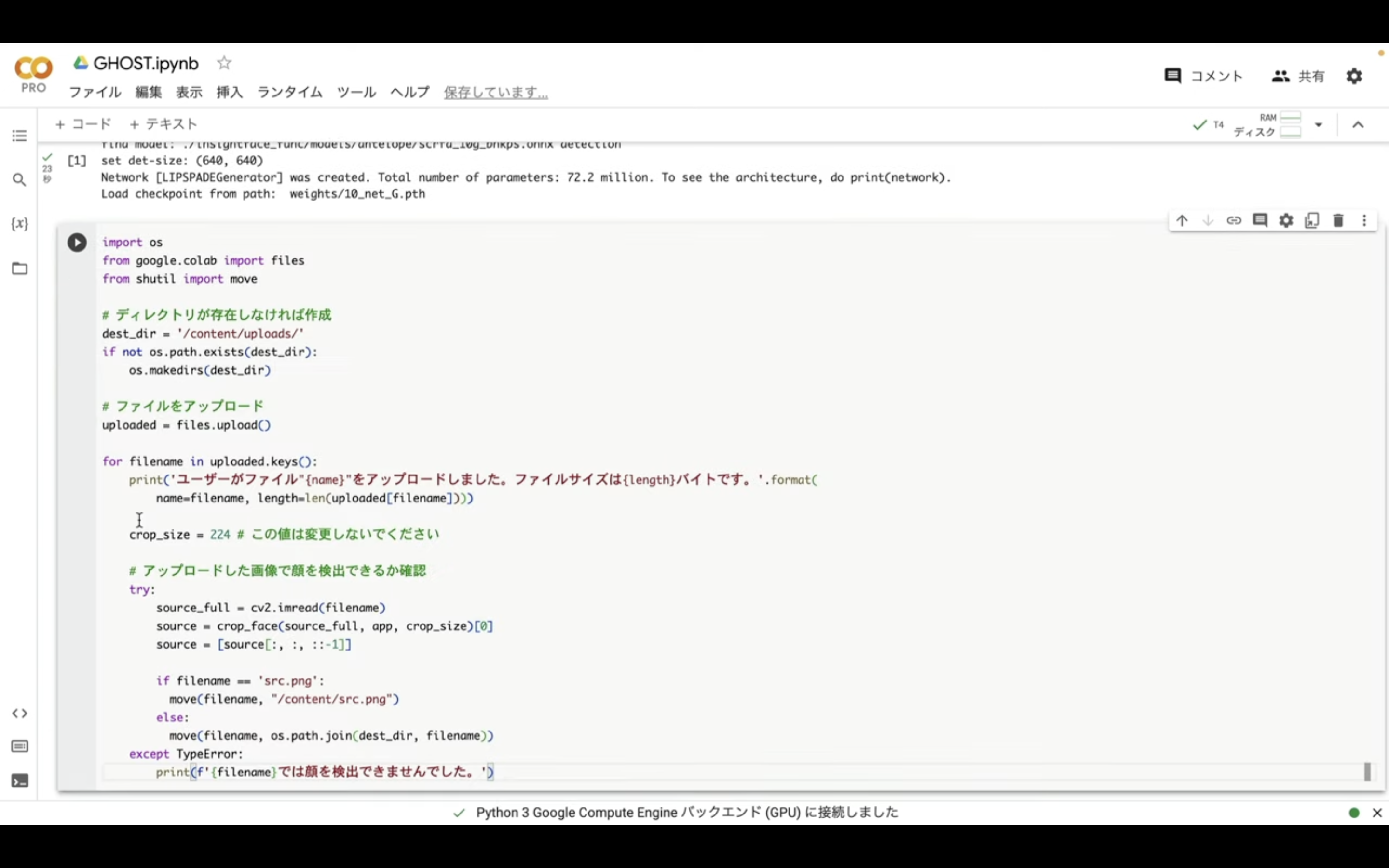
そして追加されたテキストボックスに先ほどコピーしたテキストを貼り付けます。
テキストを貼り付けたら再生ボタンを押します。
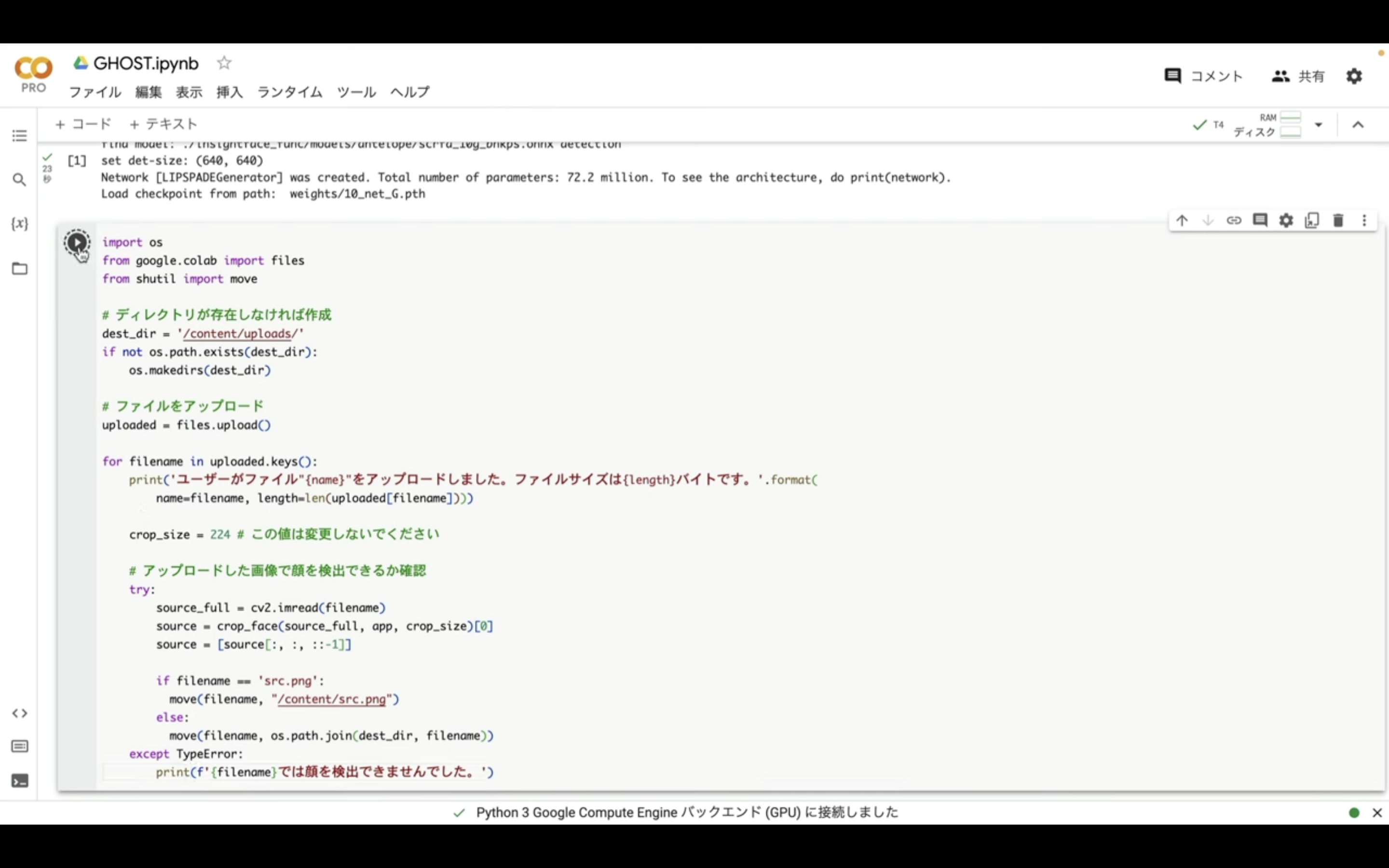
そうするとファイルをアップロードするためのボタンが表示されます。
このボタンをクリックします。
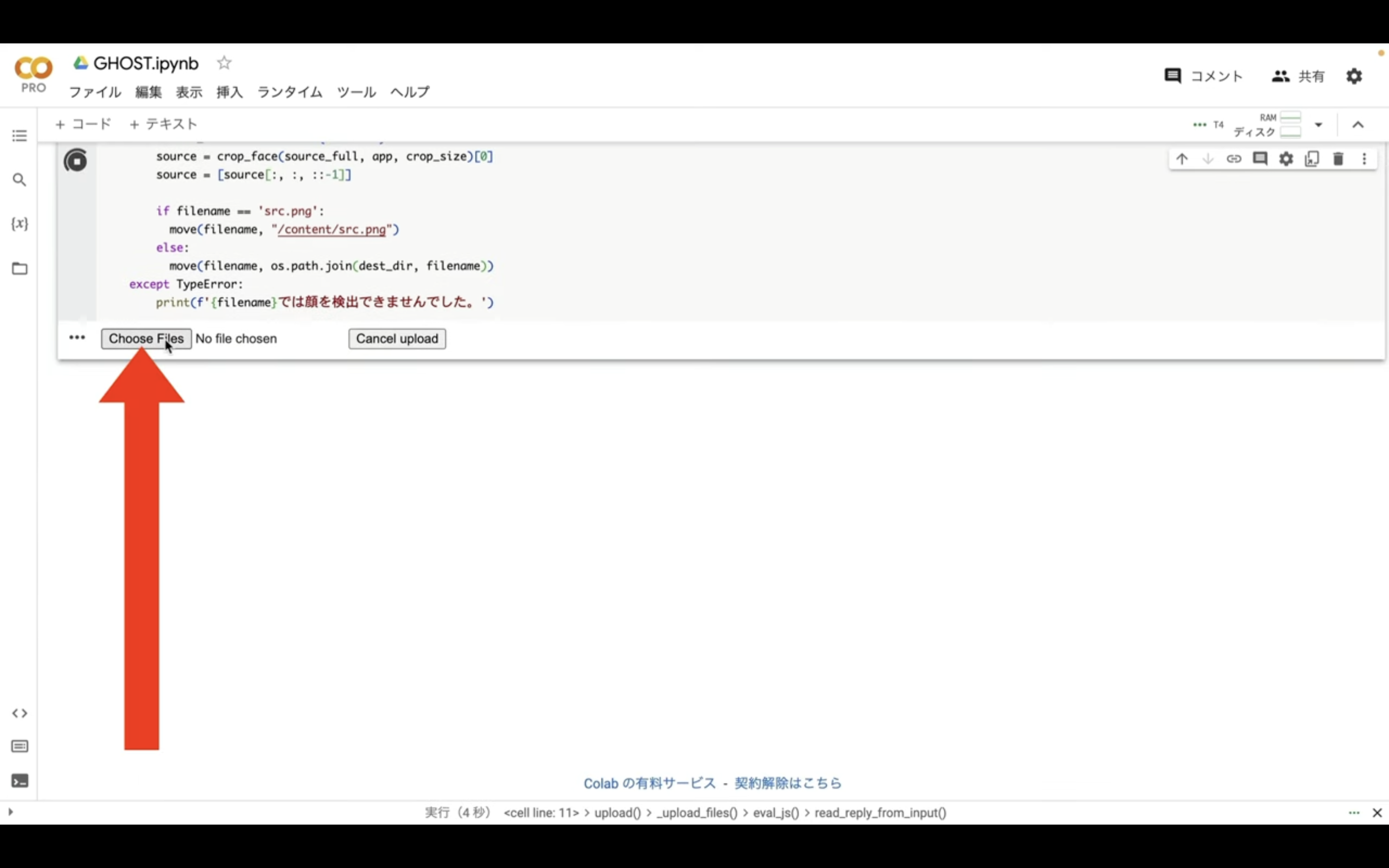
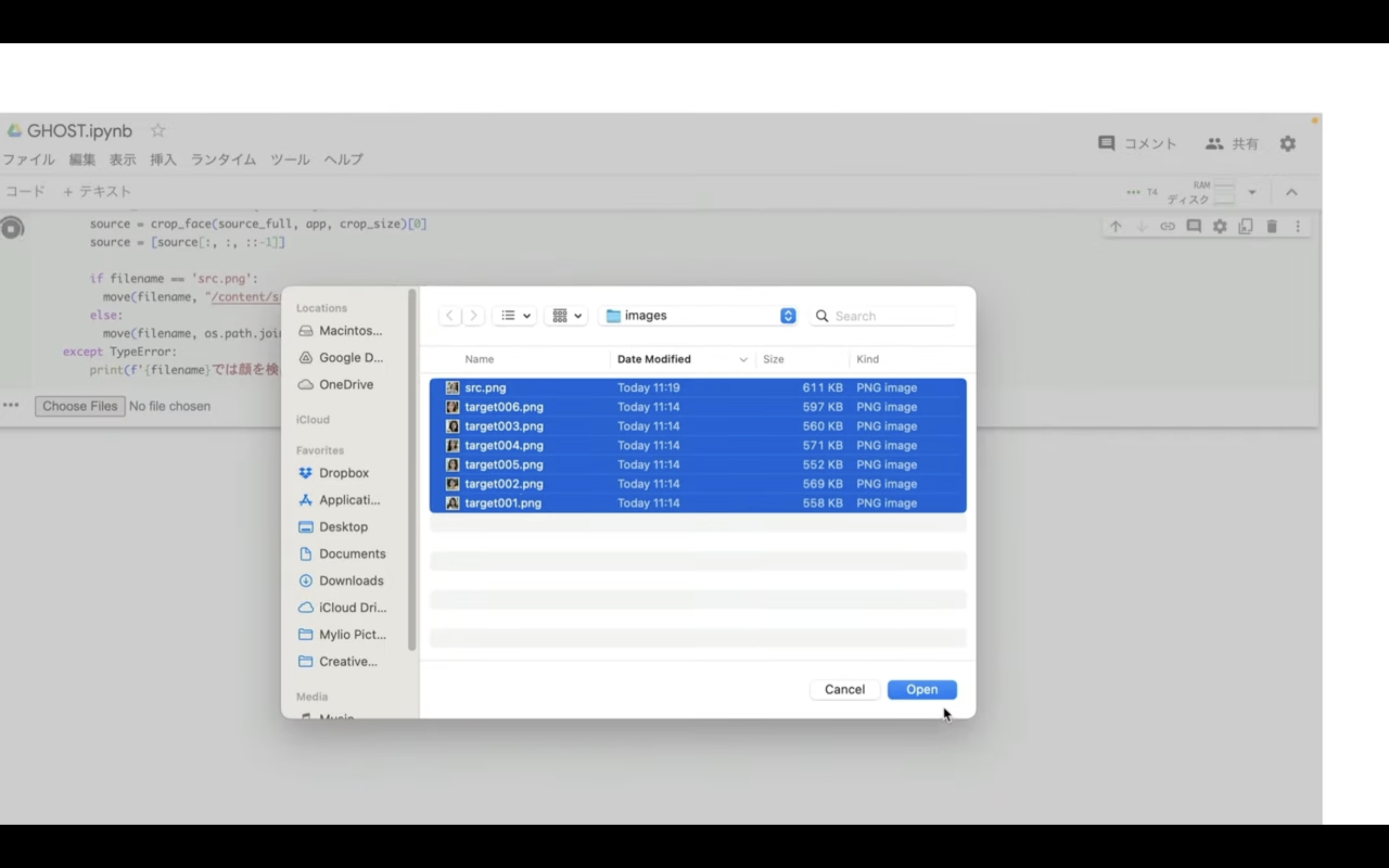
ファイルの選択画面が表示されるので、ディープフェイクに利用する画像を選択します。
ディープフェイクに指定するファイルの名前は必ず「src.png」という名前にしなければいけません。
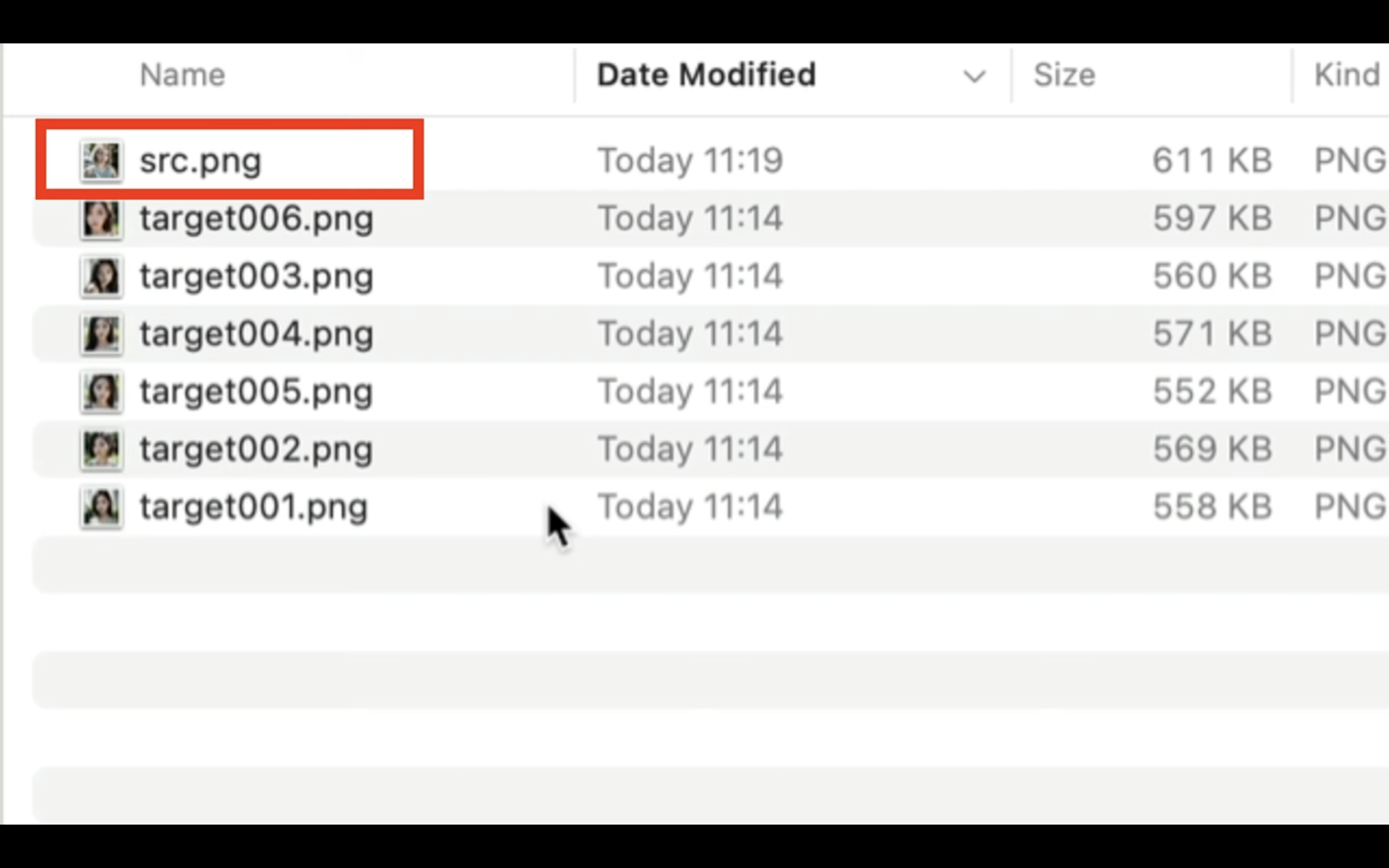
また、ディープフェイクのもとになるファイルは半角英数字で指定することをおすすめします。
これらのファイルを選択したら、「Open」ボタンをクリックします。
そうするとファイルのアップロードが開始されます。
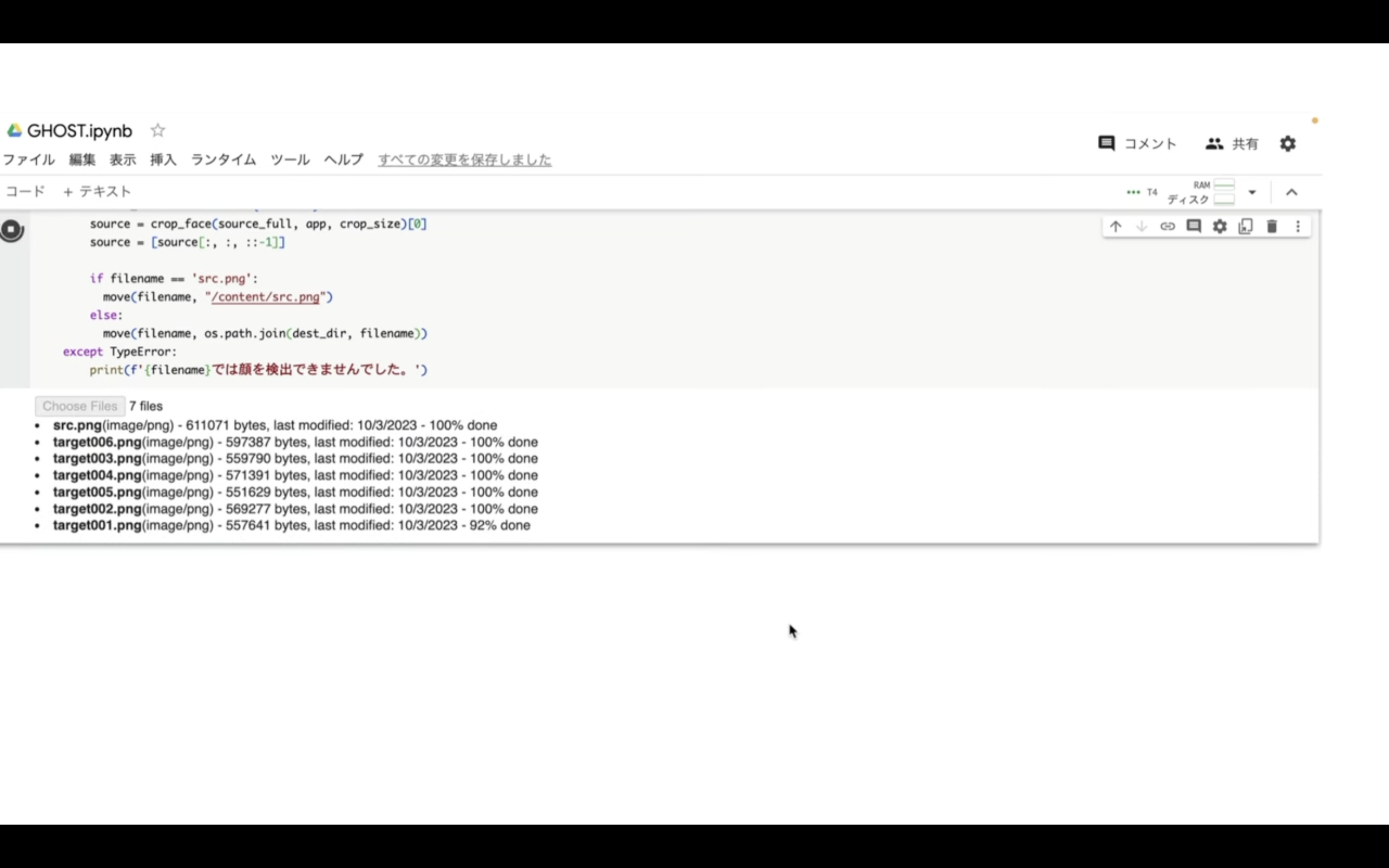
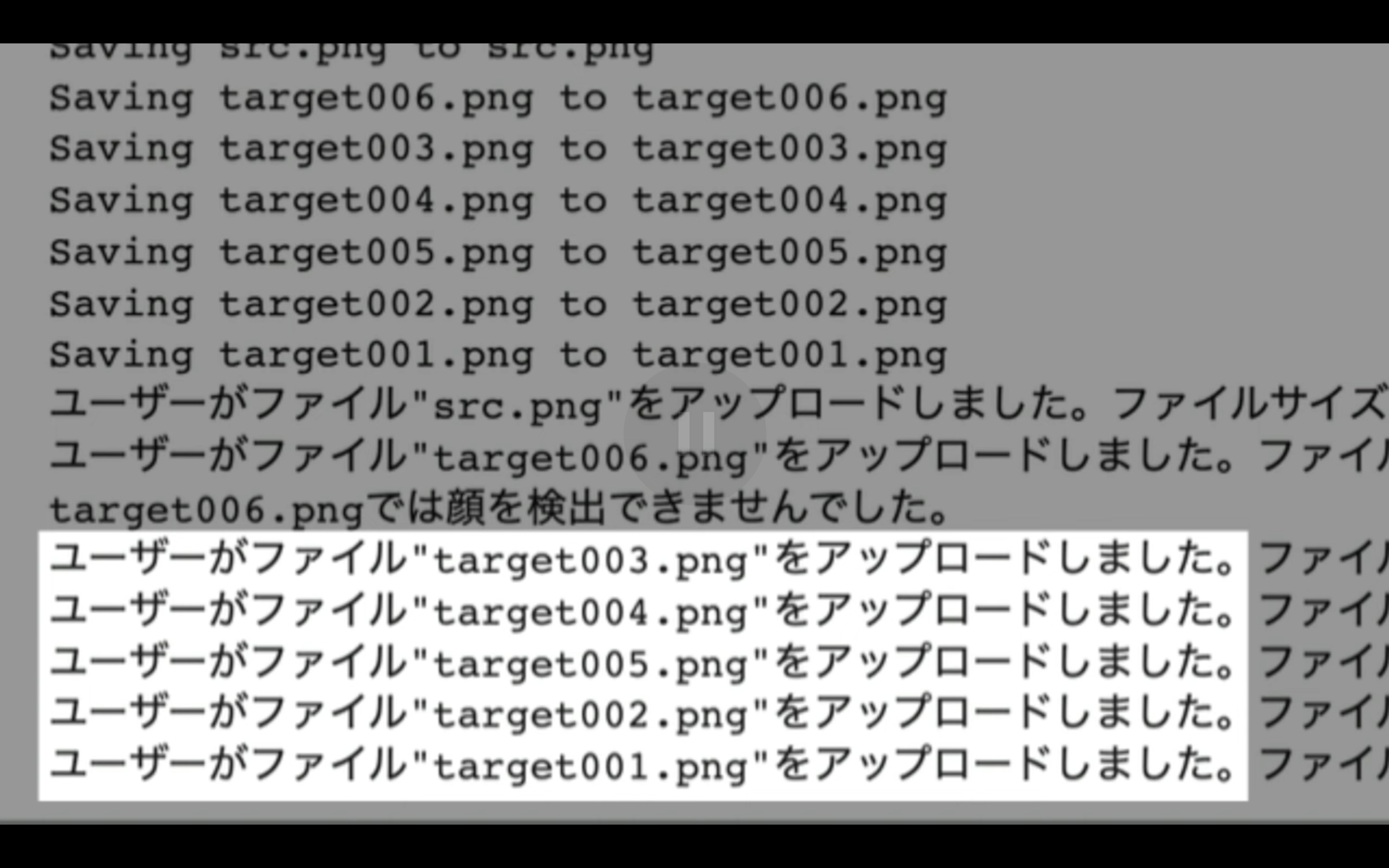
ファイルのアップロードが完了したら、次に顔の認識チェックが実行されます。
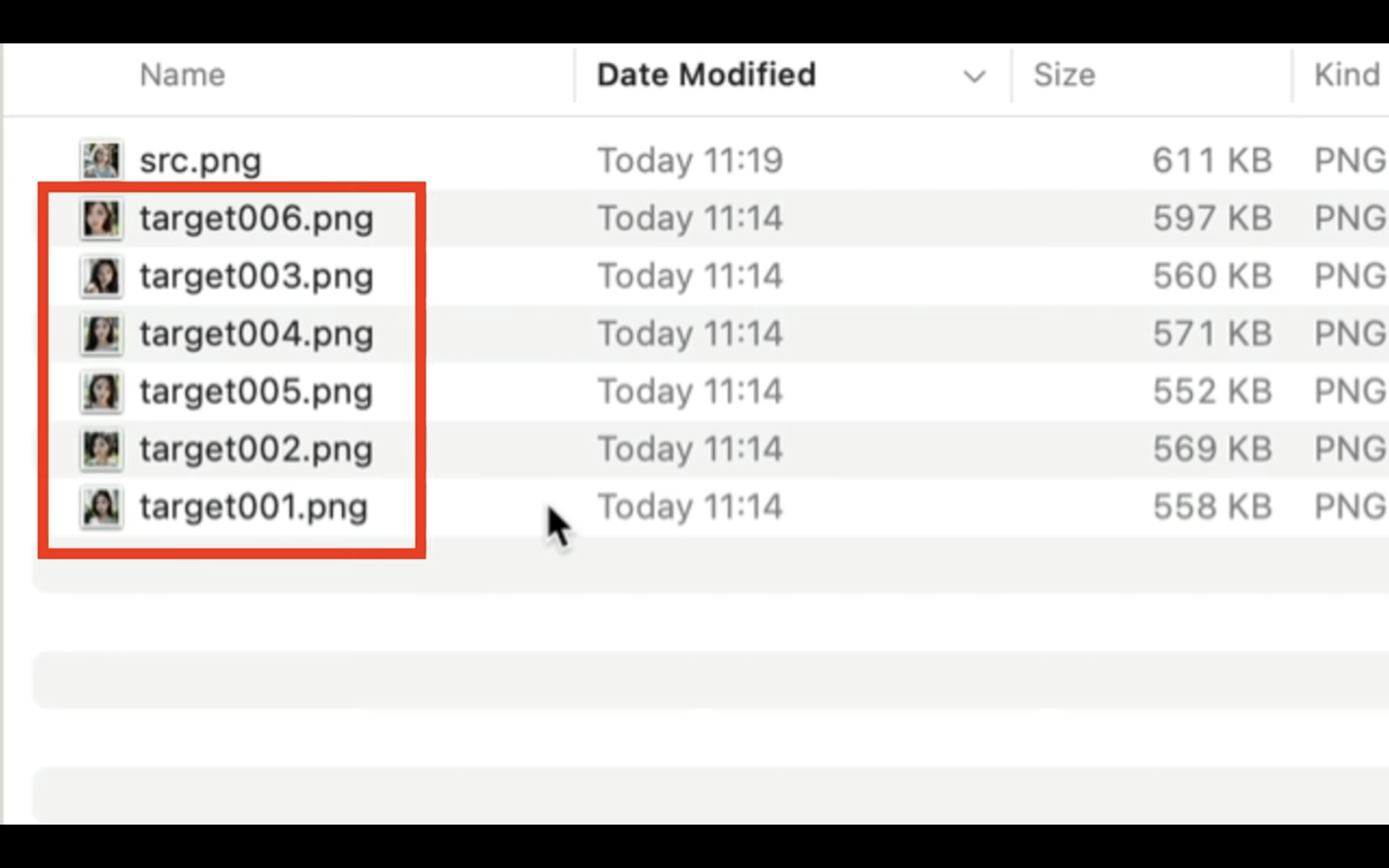
この段階で顔が認識されない場合は、このような表示になります。
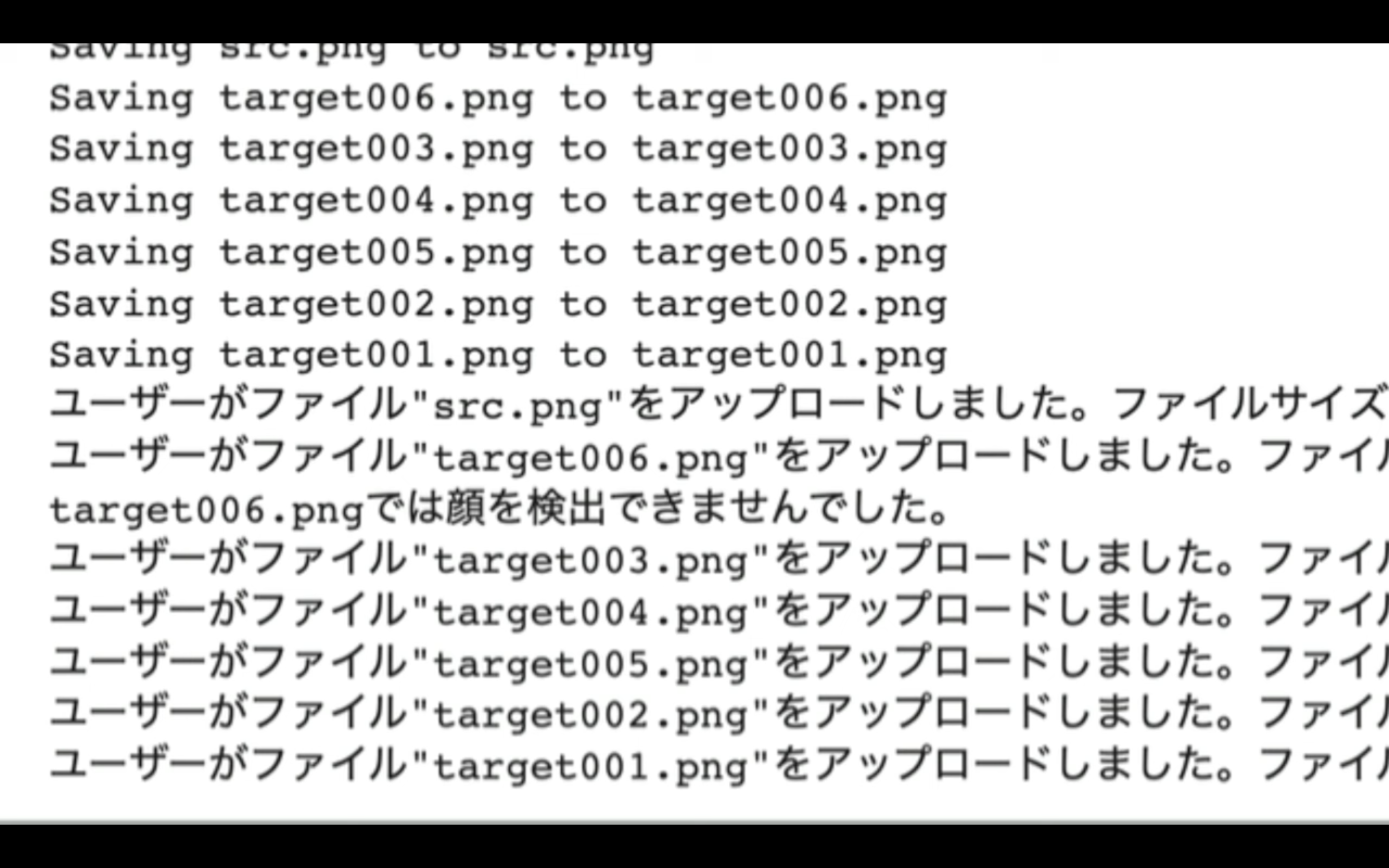
今回の場合は、「target006」というファイルが認識されなかったようです。
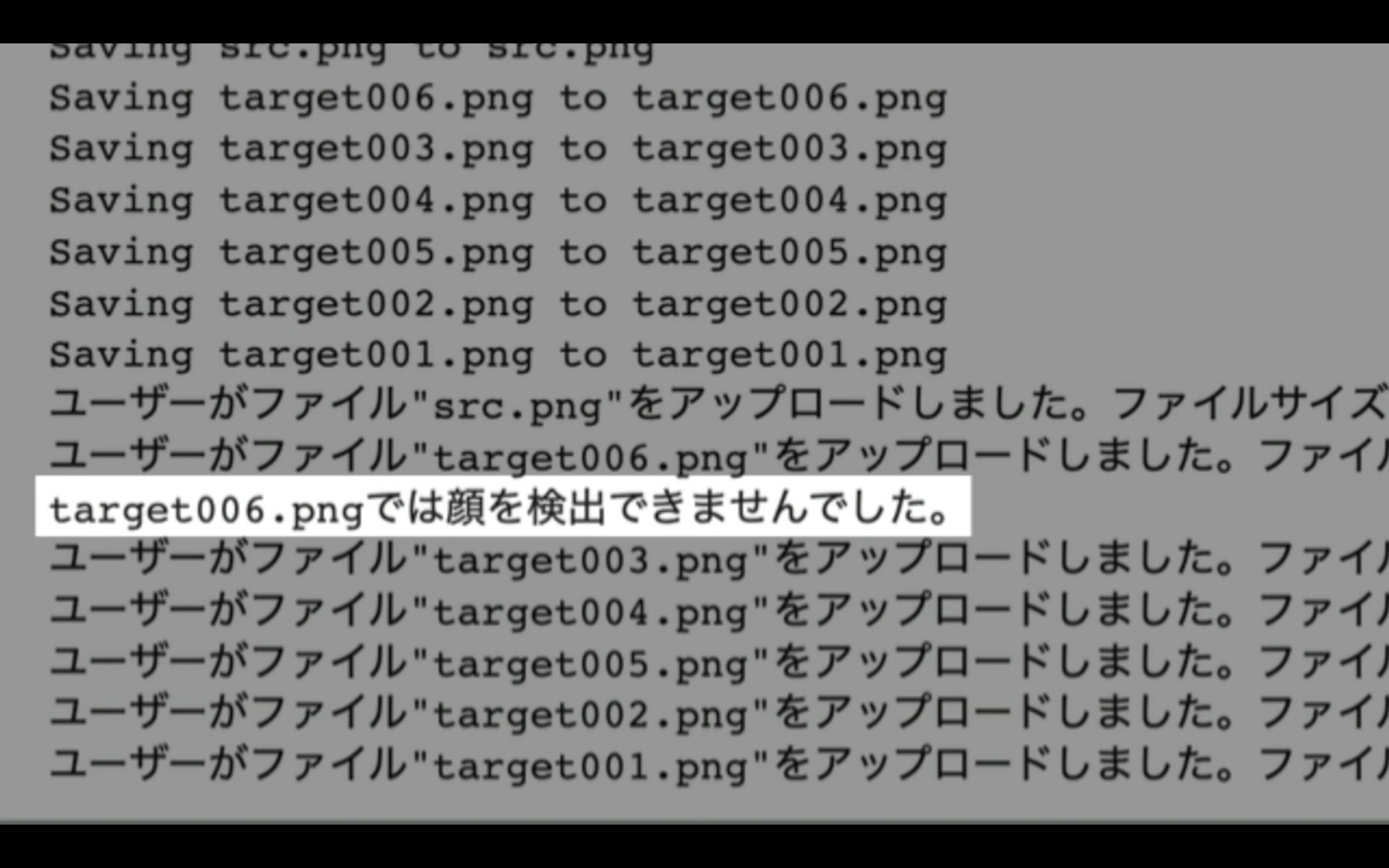
ただし、その他のファイルはアップロードできたので、このまま操作を続けましょう。
以下に貼ってあるテキストをコピーします。
import glob
import os
from datetime import datetime
import subprocess
import shutil
# 現在の日時を "YYYYMMDD_HHMMSS" のフォーマットで取得
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# そのタイムスタンプを新しいディレクトリ名として使用
dest_dir = os.path.join("/content", timestamp)
# ディレクトリを作成
os.makedirs(dest_dir)
print(f"ディレクトリ'{dest_dir}'を作成しました。")
source_full = cv2.imread("/content/src.png")
source = crop_face(source_full, app, crop_size)[0]
source = [source[:, :, ::-1]]
# '/content/uploads/' ディレクトリ内の全ファイルを対象として処理
for target_path in glob.glob('/content/uploads/*'):
target_filename = os.path.basename(target_path)
target_full = cv2.imread(target_path)
full_frames = [target_full]
target = get_target(full_frames, app, crop_size)
batch_size = 120
START_TIME = time.time()
final_frames_list, crop_frames_list, full_frames, tfm_array_list = model_inference(full_frames,
source,
target,
netArc,
G,
app,
set_target = False,
crop_size=crop_size,
BS=batch_size)
if use_sr:
final_frames_list = face_enhancement(final_frames_list, model)
result = get_final_image(final_frames_list, crop_frames_list, full_frames[0], tfm_array_list, handler)
cv2.imwrite(f"{dest_dir}/{target_filename}", result)
# 作成したディレクトリをZIPに圧縮してダウンロード
shutil.make_archive(timestamp, 'zip', dest_dir)
files.download(f'{timestamp}.zip')
テキストをコピーしたらGoogleコラボの画面に切り替えます。
コードというテキストをクリックして新しいテキストボックスを追加します。
追加したテキストボックスにコピーしたテキストを貼り付けます。
これで複数のディープフェイクの画像を一括で生成するための準備が整いました。
それでは早速生成してみましょう。
再生ボタンをクリックします。
そうすると、処理が開始されます。
処理が完了すると、生成したディープフェイクの画像を一つのチップにまとめたファイルが自動的にダウンロードされます。
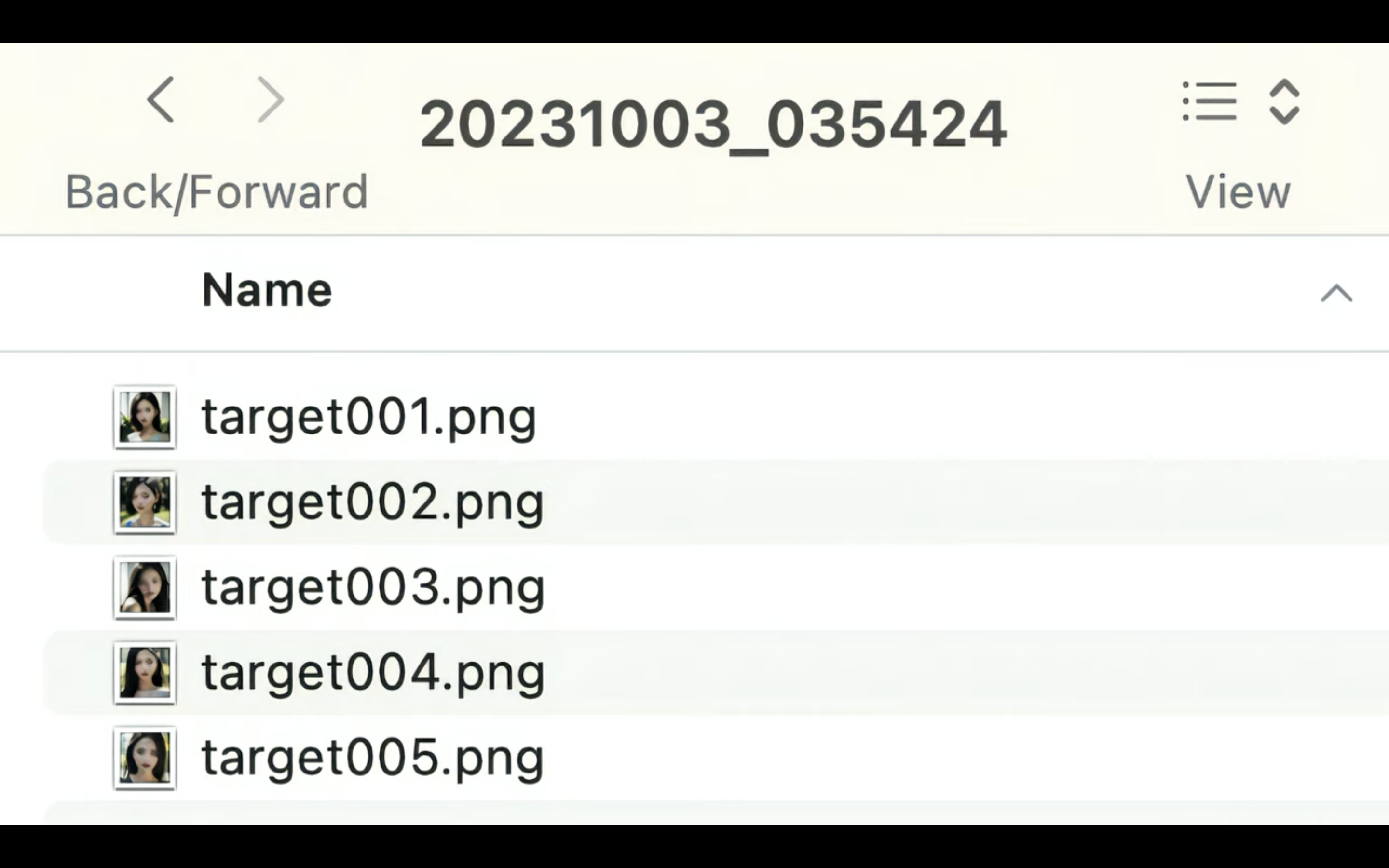
あとは、ダウンロードされたファイルを解凍して、生成された画像をご確認ください。
ZIPファイルを解凍すると、このように複数枚のディープフェイクの画像が確認できると思います。
是非お試しください。






