

▶︎動画でも話してるので、文章読むのが面倒な方はこちらをみてもらえればと思います。
今回はELYZAをGoogle Colabで動作させる方法について解説します。

これを読めば誰でも簡単にクオリティーの高いAI美女が作れるようになっているので興味がある人は、下のバナーをクリックして購入してみてね🎶

目次
ELYZAをGoogle Colabで動作させる方法について
ELYZAは日本製の大言語モデルです。
大言語モデルとは、AIの頭脳のようなものだと考えると分かりやすいです。
今回は、このELYZAをGoogle Colabで動作させていきます。
もしもGoogle Colabというキーワードが分からない場合は、詳細を解説している動画のリンクを概要欄に貼っておきますので、そちらをご確認ください。
Google Colabのサイトにアクセス
まずはGoogle Colabのサイトにアクセスします。
ここからの流れは下記に詳細リンクを貼っておきますので、そちらからご参照ください。
上記の記事ではハードウェアアクセラレーターはT4 GPUを選択していますが、ELYZAではメモリーを多く使うので、A100 GPU以外ではメモリーエラーになるので、今回はA100 GPUを選択します。
なお、A100 GPUは有料版のGoogle Colabでしか利用できません。
そのため、この動画では有料版のGoogle Colabで解説を進めます。
これで、Google ColabでELYZAを動作させるための準備が整いました。
Google ColabでELYZAを動作させる
それでは早速、実行していきましょう。
以下に貼ってあるテキストをコピーします。
%cd /content
!apt-get -y install -qq aria2
!pip install -q xformers==0.0.20 triton==2.0.0 -U
!git clone -b v2.5 https://github.com/camenduru/text-generation-webui
%cd /content/text-generation-webui
!pip install -q -r requirements.txt
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/config.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/generation_config.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o generation_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/pytorch_model-00001-of-00003.bin -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o pytorch_model-00001-of-00003.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/pytorch_model-00002-of-00003.bin -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o pytorch_model-00002-of-00003.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/pytorch_model-00003-of-00003.bin -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o pytorch_model-00003-of-00003.bin
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/pytorch_model.bin.index.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o pytorch_model.bin.index.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/special_tokens_map.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o special_tokens_map.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/tokenizer.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o tokenizer.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/tokenizer.model -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o tokenizer.model
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/elyza/ELYZA-japanese-Llama-2-13b-instruct/resolve/main/tokenizer_config.json -d /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct -o tokenizer_config.json
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://github.com/camenduru/japanese-text-generation-webui-colab/raw/main/Assistant.png -d /content/text-generation-webui/characters -o Assistant.png
!aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://github.com/camenduru/japanese-text-generation-webui-colab/raw/main/Assistant.yaml -d /content/text-generation-webui/characters -o Assistant.yaml
!echo "dark_theme: true" > /content/settings.yaml
!echo "mode: 'instruct'" >> /content/settings.yaml
!echo "instruction_template: 'Llama-v2'" >> /content/settings.yaml
%cd /content/text-generation-webui
!python server.py --share --settings /content/settings.yaml --xformers --load-in-8bit --character Assistant --model /content/text-generation-webui/models/ELYZA-japanese-Llama-2-13b-instruct
テキストをコピーしたら、Google Colabの画面に戻り、テキストボックスに先ほどコピーしたテキストを貼り付け、再生ボタンを押します。
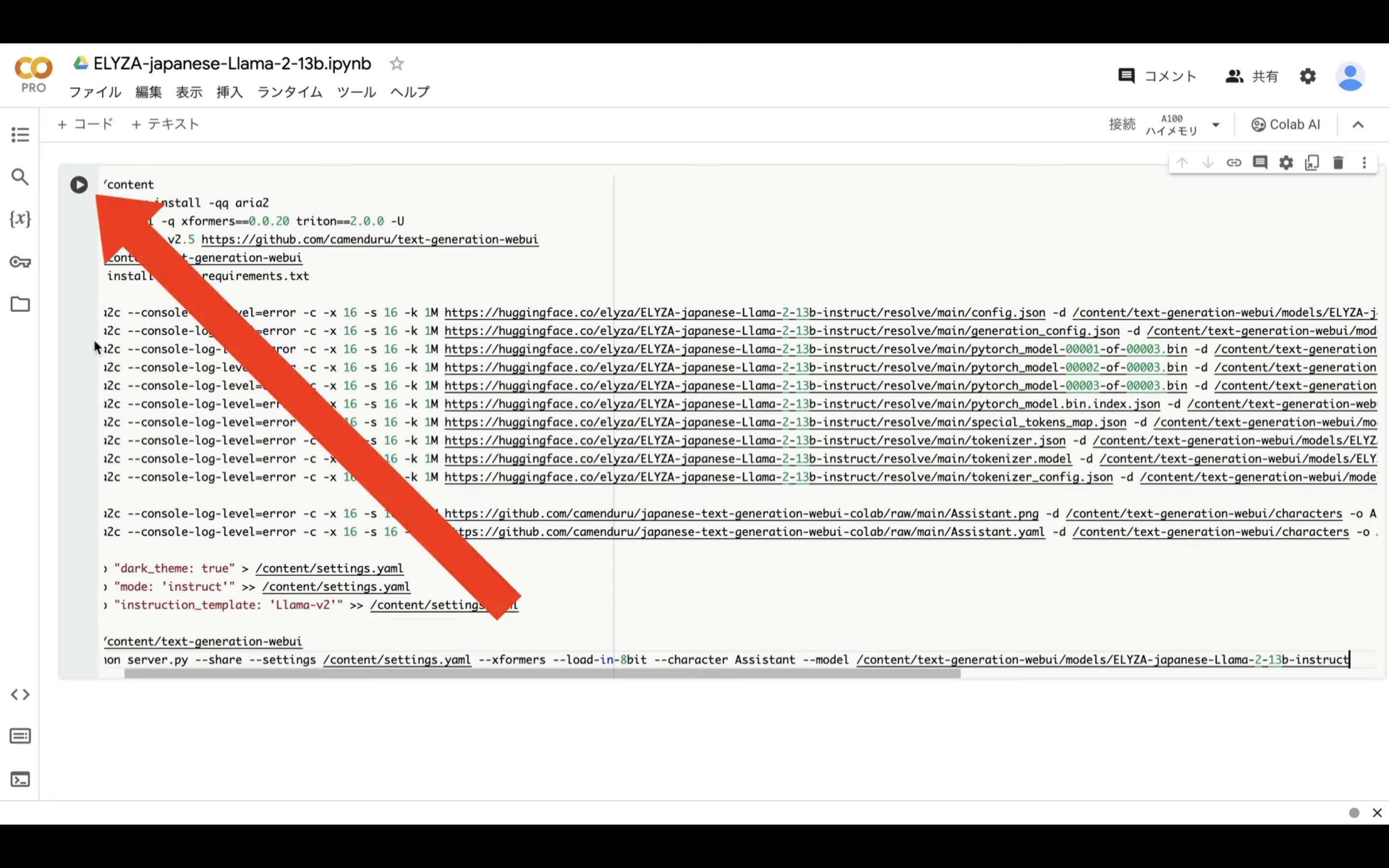
これで貼り付けたテキストの内容が実行されます。
この処理には5分以上かかると思います。
しばらく待っていると、このようなリンクが表示されます。
このようなリンクが表示されたら、「gradio」と書かれているリンクをクリックします。
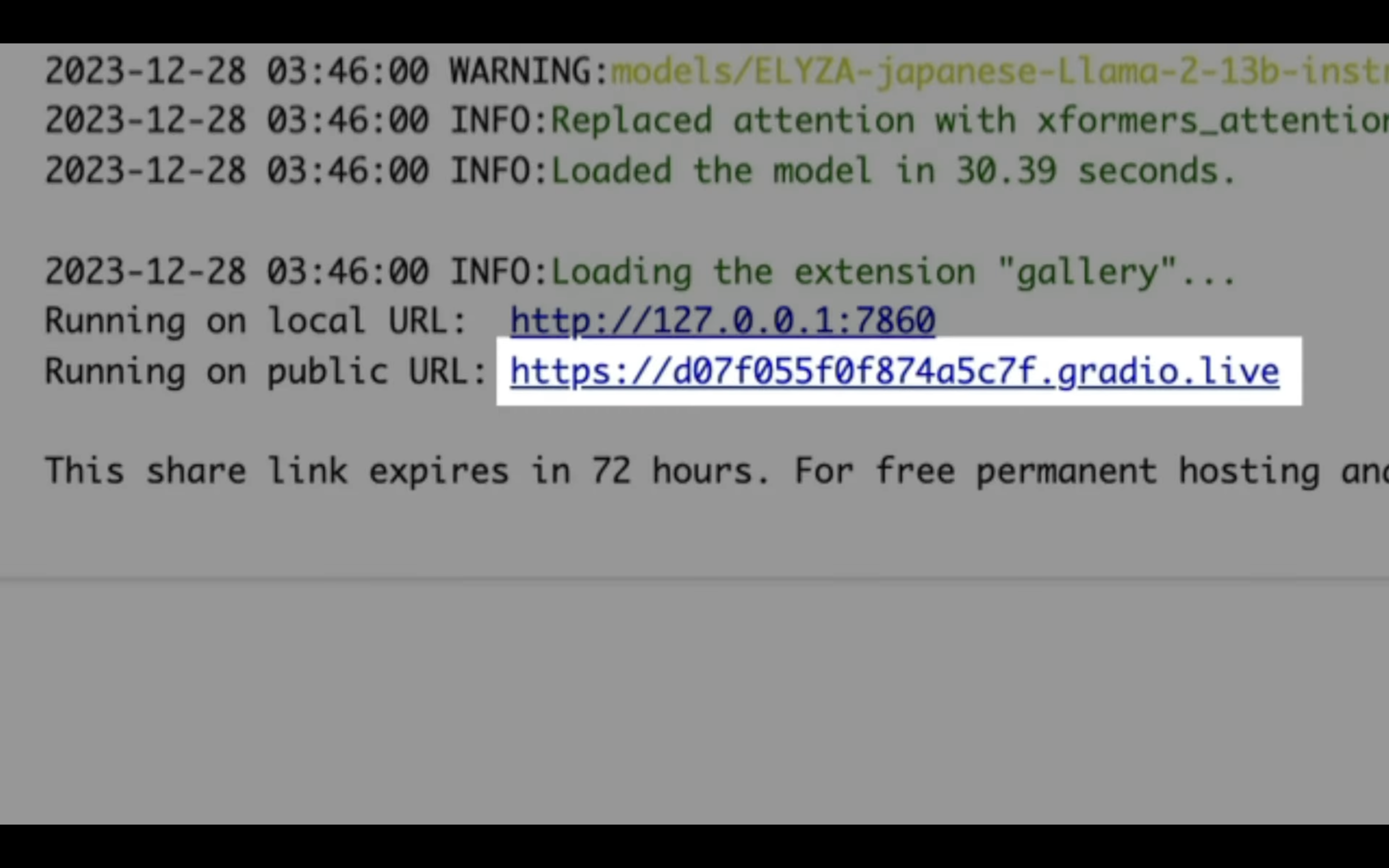
そうすると、ELYZAに指示を出すことができる入力ボックスが表示されます。
ELYZAに指示を出してみよう
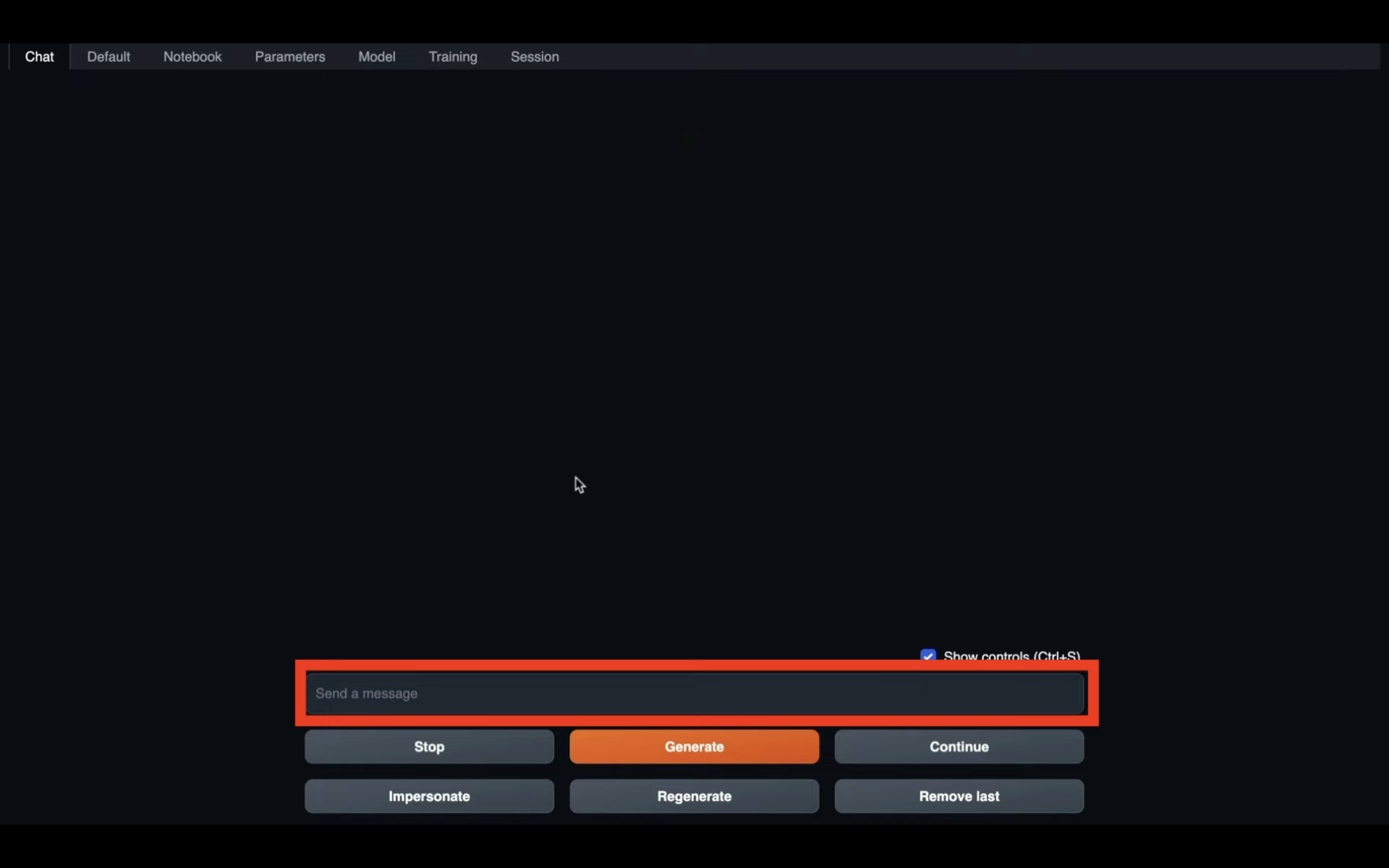
それでは早速、指示を出してみましょう。
今回は、このような指示にしてみました。
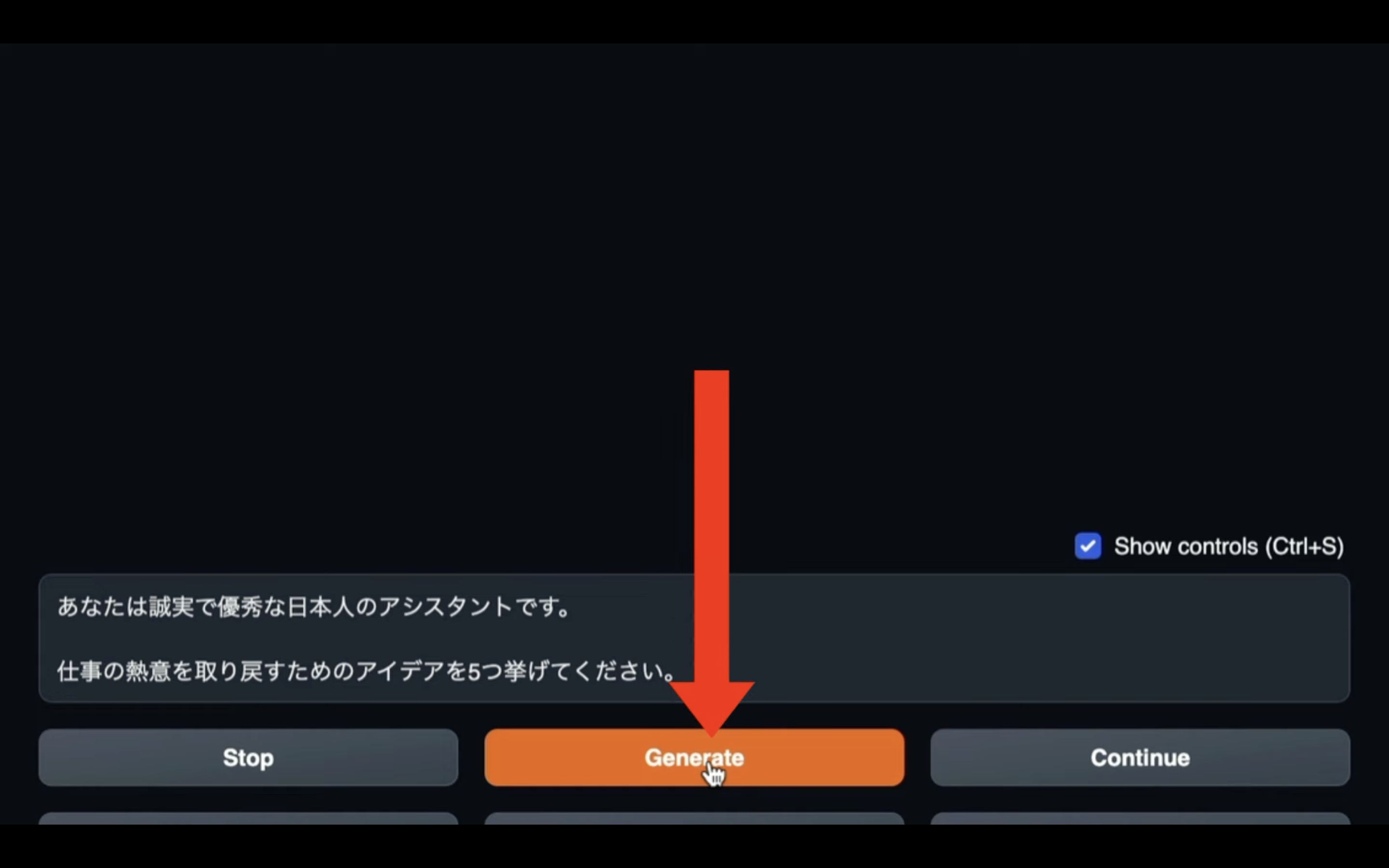
「Generate」ボタンをクリックします。
そうすると、入力したテキストが画面の上部に表示されます。
そして、そのテキストの下にELYZAの回答が表示されます。
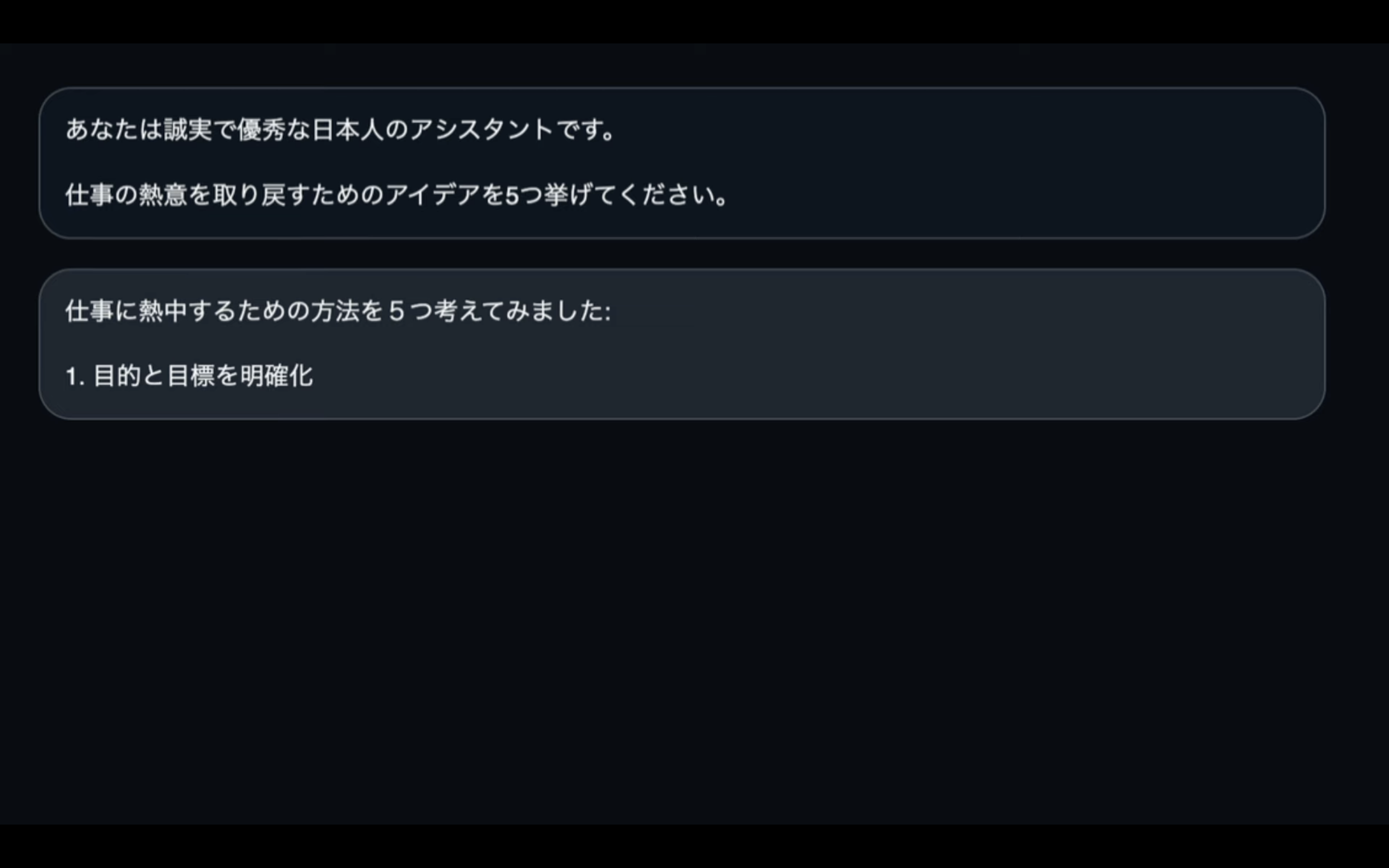
回答が表示されていく速度は、このぐらいの速度だと思います。
入力テキストの左上にドットのローディングのアイコンが表示されている間は、回答が処理されています。
もしもこのアイコンの表示が消えてさらに回答が途中だった場合は、続きを表示してもらうように依頼します。
回答の続きを表示してもらう
続きを表示してもらうためには、「Continue」のボタンを押します。
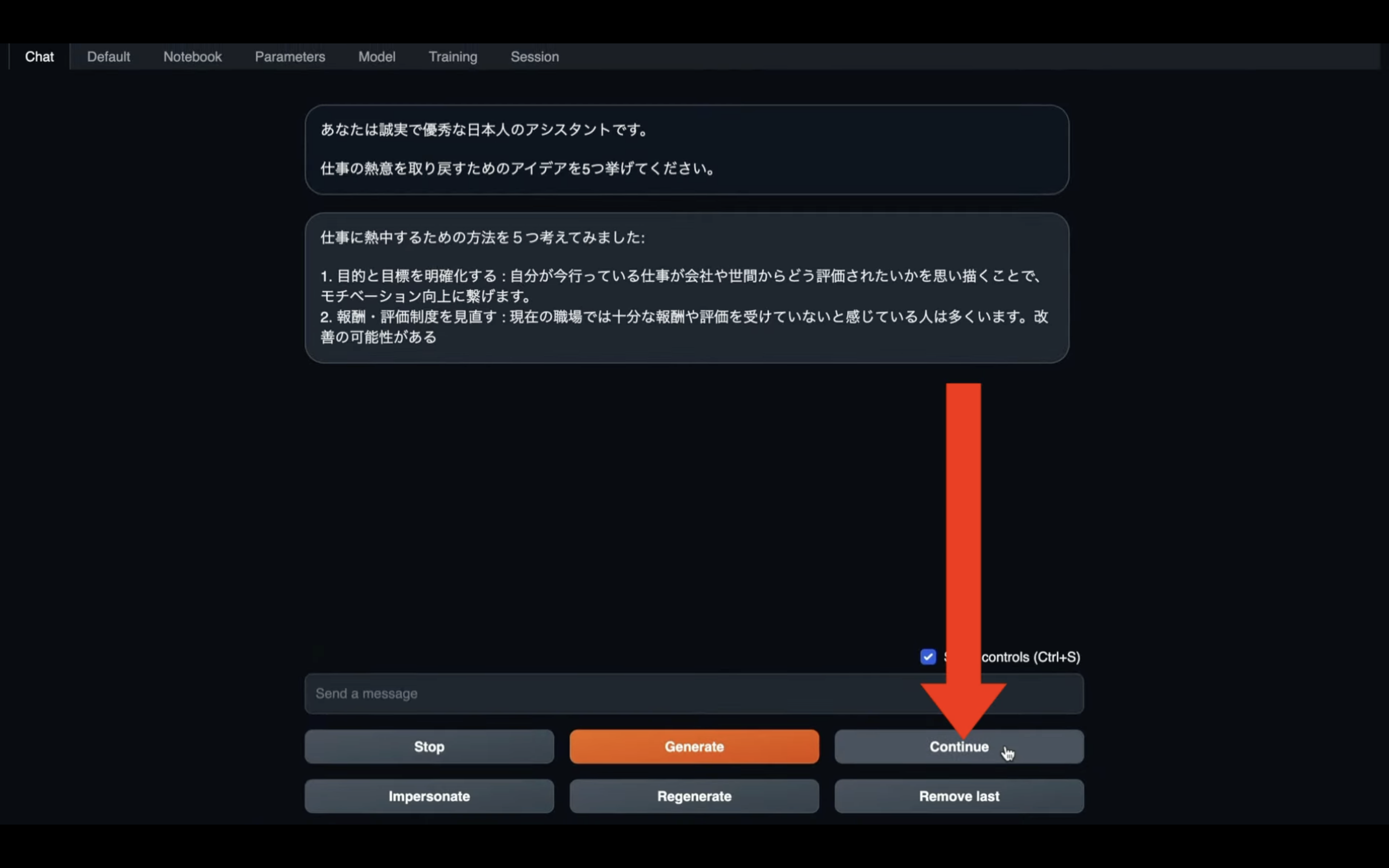
そうすると、回答の続きを表示してくれます。
回答が途中で途切れるたびに、この操作を繰り返します。
何度か繰り返すと、全ての回答が返ってきます。
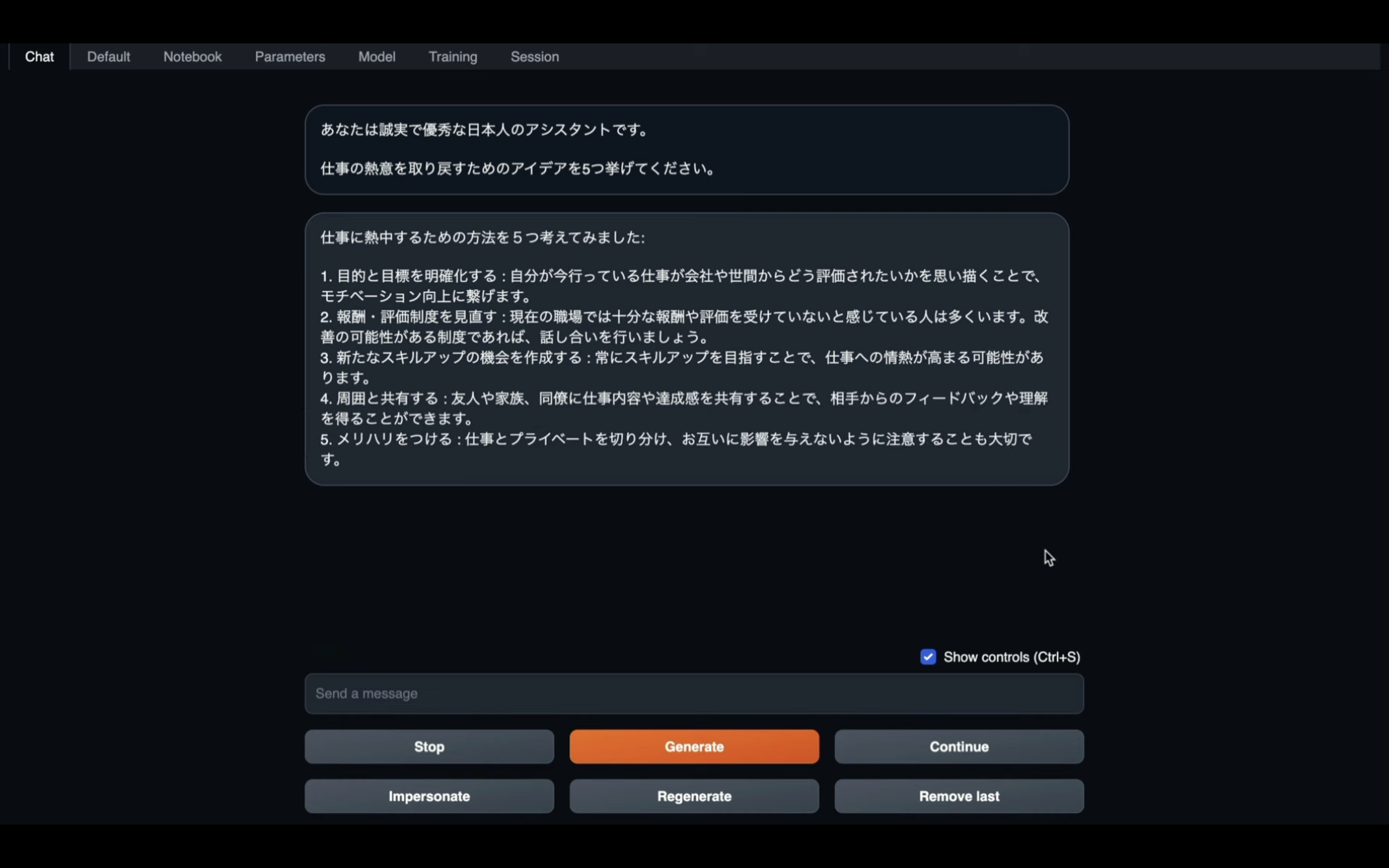
この動画では、回答が全部返ってくるまでの様子を早送りにしていますが、実際は数分程度かかるかもしれません。
Google ColabでELYZAを動作させる方法についての解説は以上です。
是非お試しください。






